@tag: #PKM #知识管理 #Zettelkasten #卡片盒笔记法 #Luhmann
@link:: PKM.03.什么是卡片盒笔记法
sspai链接: https://sspai.com/post/75940
01.从这里开始
目前我在用的笔记系统,用一句很简单的话概括就是:本地markdown文件 +Dropbox网盘同步,同时用 Vscode 项目把整个笔记目录管理起来。
大概几年前,我正在 Evernote 、有道云笔记、OneNote之间反复横跳。当时还没有 Notion,也没有RoamResearch,甚至PKM(个人知识管理)都很少有人提及。
最后还是选择了本地 Markdown这种“看似不便”的方式,毕竟原生的 Markdown有种种缺点(图片管理、没有 Metadata、不支持复杂排版),本地文件的方式摆脱不了树状文件夹的笔记结构… 甚至在当时缺少非常顺手的编辑器。但这些年修修补补也一直用下来了,上面提到的种种缺点也都改善或规避,期间也尝试过 Notion、RoamResearch、Logseq,但这种 “基于本地 Markdown”的笔记一直都是我的笔记系统基本盘。

这种方案的好处是:
- 数据完全属于自己,Dropbox网盘 + 自己写的定时脚本备份到 Git ,双重措施可以确保笔记不会丢失,也能通过 Git的历史追溯修改历史、查看笔记系统的生长过程;
- 最好的同步体验(Dropbox) + 最好的现代编辑器(Vscode):Dropbox的多设备同步近乎实时,并且增量同步非常适合 Markdown 这种轻量文本,如果上网不便可以用坚果等其他同步盘替代,如果你用 苹果全家桶且能忍受 iCloud Drive的同步1,它也是可以的 。至于最好的编辑器…. 还是看个人习惯吧,现代的编辑器诸如 Sublime、Atom,以及 编辑器原旨主义宗教继承人 NeoVim、Spacemacs… 它们都非常棒,这些 「Code Editor」 功能大同小异,看自己习惯和信仰;
- 除了传统编辑器,笔记文件库还可以用多种软件打开:如果要书写体验可以用 Typora(我现在正用 Typora 写这篇文章),如果需要双链的鸟瞰图可以用 Obsidian(借助 Obsidian的双链实现网状结构),同时也有基于文件夹的树形结构。
在网状结构笔记大行其道的今日,树形结构依然是人类的对知识的最佳认知结构2。 - Markdown是一种“源文件”,可以转换为各种格式输出。我会把笔记通过 Hexo生成博客(需要一些脚本做 Markdown的转换,例如修改图片路径适应Hexo的目录3,从而实现 笔记到博客的一键发布),这种“笔记即发布为博客”也是一种 数字花园4的实践,我的笔记公开部分放在了gitee上。此外,使用 pandoc 将 Markdown 导出为PDF、PPT、DOC等等格式应付各种场合,「一处写作,多处发布」。
当然 “本地 Markdown 文件”这种方案也有一些不便:
- 块引用:Vscode 和 Obsidian都已经支持了使用
#标题作为块引用的最小单元(例如[[笔记名字#标题名]]这样 ) ,但不能支持更细粒度的块了, 相比较 Logseq 和 RoamResearch等等都支持的“行级别的块引用”; - 缺少好用的移动端(iOS/Android),不过我在手机上很少直接编辑笔记,如果有突然的想法我会记录到 Drafts,所以对于手机端的要求是方便查/阅:
- 如果你用 Dropbox同步,1Writer(Android ) 、MWeb(iOS)、Editorial(iOS) 都可以;
- 如果你用 Git同步,Working Copy (iOS)是我的第一选择,Noteshub作为替补(iOS)
- 图片管理:早年的 Markdown编辑器贴图很麻烦, 但借助插件和更新的编辑器,无论 Vscode 或者 Obsidian 都支持使用
Ctrl+v的傻瓜方式贴图,和富文本编辑器相比,对图片的使用已经不那么麻烦了。我把图片存储在项目下的image文件夹,用dropbox一起同步。好处是笔记无论搬到 Git 还是 Hexo博客,这些都能很好的支持本地图片,也不担心图床失效的问题。 - Markdown的表达能力的缺陷:
- 没有Metadata:比如 Evernote的笔记里还记录了 创建位置、修改时间等等Metadata的, 虽然说修改时间也能从文件属性里读出来,但如果换新电脑or 移动一下文件夹这个时间戳就失灵了。Markdown 的话只能通过 YAML Front Matter 存储这类信息,但这玩意不属于原生语法,各家App 的支持也不尽相同,会造成显示的混乱。
- 不支持复杂排版,例如双列、图文混排等等样式。公平的说,复杂排版本来就不是 Markdown 该做的事情,Markdown 实现的是易记且便于书写的标记语言,换个角度说,支持复杂排版的标记语言写起来一定不方便(诸如 LaTex、HTML等等)。当然实现图片排版可以通过往 Markdown 里加一些 HTML 来支持,例如 Obsidian的主题 Blue-Topaz 提供了类似的功能,但我不用,这些不是原生的 Markdown 语法,可能这个 App 里支持但换另一个 App 就不识别了
关于云笔记服务的数据安全多说几句,大厂的笔记产品,虽然有靠谱的技术保证服务稳定性,但也有潜在的不便:
- 内容审核:国内大厂头上的达摩克利斯之剑,具体可以参考金山删除用户文档的事儿,以及早年的坊间传闻“百度云和谐了我的正常视频!”,为什么是传闻,因为没人能拿出证据证明视频的清白🤓
- 产品生命周期:我也在BAT工作过,了解一个产品的出生到下线整个过程和决策,大厂产品也会有下线的那一天。当然下线前会给用户充分的迁移时间,but, 迁移也是成本!。此外,国外大厂也好不到哪儿去,比如Google 关闭过的一众服务(Reader、Picasa、Wave等等…),以及因为服务条款变更而关闭国内服务等等(Yahoo就是你!)
02.笔记的目录结构

我的笔记系统有6个目录(如上图),分别存储不同的笔记:
- ① Inbox/:临时笔记,很多情况下一篇笔记不会立刻写完,可能需要几天的酝酿和资料收集,在这一阶段的笔记存储在这里,进一步组装和成型。每天我只需要关注这里就可以想起最近在学哪些东西;
- ② Project/:项目笔记,“万事皆可当项目!”,除了我们的工作,其他的个人事务也可以用项目管理的方式:有最终目标、有最终完成时间(DDL)、有阶段性时间和关键成果(KP)。项目笔记的特点是:没有过多的知识性信息,大都是时间点和具体操作;
- ③ Personal/:带有个人信息的笔记,例如一些账单、体检报告、会员卡号、甚至旅行箱密码等等… 这里存储的更像是“备忘录”而非“知识性笔记”。把这部分单独存放的好处是,当要分享自己的笔记时,我可以很放心的分享另外几个笔记目录,这是一种信息隔离的思想;
- ④ Code Primer/: 永久笔记1(专业知识的笔记放这里)。题主是一个程序员,从编程语言、架构设计、中间件、大数据等等都有涉及,这个目录下的笔记数量是最多的,子分类也是最多的。后面会说这部分如何分类;
- ⑤ Scriptorium/:永久笔记2(专业知识之外的关注),比如作为一个喜欢文史哲的码农,这个文件夹下面有生产力工具、财经、摄影、流行文化、心理学和哲学等等..
- ⑥ Archive/: 归档,对于上面1/2/3/4不再感兴趣的、长期用不到 或者不再维护的,都丢这里;
▷ 关于 2.Project 和 6.Archive 的分类:是参考了 P.A.R.A 分类法5,但没有完全照搬,只采用了两个原则,1有时间节点的是项目,应该独立出来,2不再有兴趣不再维护的资料放入归档。另外,P.A.R.A 的提出者还提到自己私人信息也会放入Area,这样可以随时放心的分享Resource,“例如体检报告、就诊记录放在名为“健康”的Area中,而Resource中存放的是运动、健康的有趣文章或者推荐的训练方案”。
▷ 对于“闪念笔记”,我是不放入这套笔记里的,我会在手机上用 Drafts 记录下来,然后 闪念笔记 要每天清空一次,有保留价值的会稍加整合放在 “①Inbox”文件夹下继续组装和完善,无保留价值的闪念笔记直接删除(像一些无价值的呓语和仅仅带有情绪抒发的碎碎念,是无继续写的价值的);用完的闪念笔记也可以不删而是归档,这样在 Drafts的归档里还是可以保留时间序的碎片的。
▷ 上面提到的 ④ 和 ⑤ 都是一个独立的 Obsidian库,为什么作为知识积累的永久笔记,不放在一个文件夹而是分开? 原因一是 如果合并,子目录就会太多,不便管理;并且 ④ 和 ⑤ 中的笔记几乎没有互相引用,所以分为两个库( Obsidian 管理引用链接的范围是库,库外的文件无法引用,属于不同库的笔记是“引用隔离”的 )
▷ 关于临时笔记(Fleeting notes)、永久笔记(Permanent notes)的概念:参考了Luhmann 的笔记分类 。但我的笔记里没有“文献笔记(Literature notes6)”这一类, 对于文献的记录和总结,我习惯都放永久笔记。这个视个人分类习惯而定,有时候把类型分的太细致反而阻碍写作的积极性。
▷ 永久笔记并不“永久”:永久笔记也在一直被更新和完善,拆成小文件、合并成大文件、增加引用链接等等。这也正是 Andy Matuschak 在常青笔记中的描述:“常青笔记的编写和组织是为了随着时间的推移不断进化、贡献和积累”,卢曼提到他的卡片盒笔记是内生长(internal growth)7的。
▷ 关于永久笔记奇怪的命名:
“Code Primer” 来自于我的编程启蒙书《C++ Primer》,
“Scriptorium”意为缮写室,中世纪制作书籍的地方8
03.永久笔记的结构
上面提到了两个永久笔记目录,如下图,左边是专业知识的笔记,右边是兴趣爱好的笔记: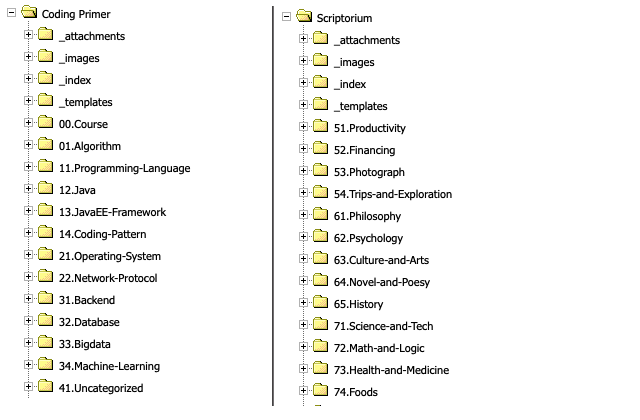
笔记结构和格式有一套守则:
- 每篇笔记的格式,遵循“原子笔记”:即一篇笔记说明白一件事情。
- 但是不强制要求每篇笔记都是“原子”的。 当我们刚涉及一个领域时,可以只从一篇记录开始,这时候笔记中各种信息可能混杂在一起,并不“原子”。随着对这个了领域的深入,笔记的内容也会不断增加,同时对这个领域也有了初步了解,知道大概如何归类了,那这篇可能会被拆分开。
- 常青笔记9中提到,笔记是生长的,一篇笔记不仅可以添加内容、当然也可以再拆分、以及与其他笔记建立引用,总之让笔记体系变成更充实、更合理的形态,这样的笔记是具有生长性的。
- 一篇完整的原子笔记应该包括:唯一标识、正文(自己的理解,避免复制粘贴)、参考文献列表

- 分类文件夹只有一级,不建立二级分类文件夹:如果某个文件夹下的笔记非常多,不得不建立二级分类的时候,我的选择是仍旧新建一级文件夹,例如
📂 11.Programming-Language文件夹下是编程语言的笔记,因为我一直都在用Java,所以Java相关笔记的积累也非常多了,这时并不在📂 11.Programming-Language的下层再建立子文件夹,而是与之平级建立了📂 12.Java文件夹。 虽然听起来不符合“分类的层级”的常识,但是好处也很明显:- 可以避免树状结构太深,笔记被藏在很深的文件夹里容易被遗忘。对于树形的层级结构,思考 “我应该把笔记放在哪个层级下面?” 也是一种思维消耗,分类强迫症患者们会因此陷入到不停的分类工作里;
- 文件夹带数字前缀,让显示顺序符合自己的需求,同时也方便目录的扩展,父类别的子类可以从1a扩充到1a、1b… 它们依然有序
- 这套带序号的文件夹分类参照自杜威十进制分类法10,同样可以套用到 Evernote、Cubox、Zotero等等其他软件中,包括知乎收藏夹、浏览器收藏夹等等,这样自己所有的资料都用一套命名体系,很方便;
- 这种平铺单层文件夹更像卢曼的卡片盒,没见过卢曼用大盒套小盒吧,小盒套小小盒吧?
- 但是如果确实需要树形结构怎么办?看下面的文件命名规则
笔记文件的命名:文件名加类别前缀,例如
Java.03b.GC案例分析.md这样一个文件名。可能有人会问,父文件夹名字叫12.Java,文件名里就不用以“Java”开头了吧?这样文件名里的“Java”是冗余信息啊。其实这里是特意而为,有个具体操作案例:Vscode里有个“文件名模糊搜索”功能,快捷键“Cmd + P”,我只需要搜索“Java GC”,这样文件名里带“Java”和“GC”的所有笔记都会被搜出来,当然 Obsidian里也有类似功能,快捷键 Cmd + O。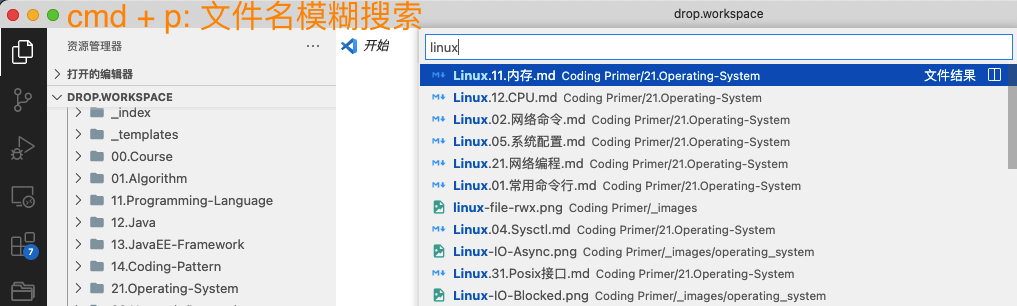
文件名的构成里除了表意的前缀,接下来还有序号,作用也是为了让相关联的笔记排序能凑在一起,同时递也方便笔记的“生长”,例如一个笔记内容太大需要拆分成2个笔记,新笔记的序号从1递增到1a即可,如果1a笔记又变大需要拆分,增加1b笔记即可。这些从一个笔记拆出来的众多子笔记,依然是保持有序的;图: 左边是 卢曼的笔记编号系统说明(笔记是如何通过前缀保持有序增长的),右边是我的笔记编号:
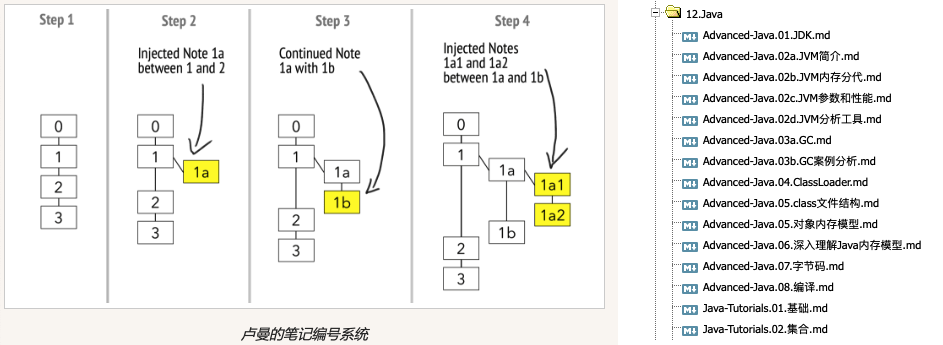
上图说明了通过卢曼的编号体系,如何在同一层笔记中表示不同的层级关系:- 第一层概念:0 → 1 → 2 → 3, 这几个笔记是平级的概念
- 当“笔记1”有了子类别:1 → 1a → 1b,其中1a、1b都“笔记1”的子笔记,若1a也有了子笔记,就用1a1、1a2继续。
通过这种命名方式组织笔记,文件夹下面的所有笔记看起来都“平铺”了,但仍可以通过文件名表达出分层的关系,也不会出现“深藏在某个子子子文件夹中的笔记”这种问题了。wiki百科里详细说明的这种方式 https://en.wikipedia.org/wiki/Zettelkasten, 卢曼的 Communicating with Slip Boxes by Niklas Luhmann 卢曼把上面的编号构成的“层” 成为slip(滑道)
“不过早对知识进行分类”,这也符合学习的习惯,刚开始接触某个领域可能只有一篇笔记,我们也不知道这个领域改如何分类,所以开始就不要想“刚开始就把笔记放在合适的分类层级上”,当随着学习的深入,笔记逐渐变大,这时候自然会拆分出新的子类别,让笔记“自然的生长”。
- Markdown 中的章节是用
#Heading来划分的,对于 Heading 的命名也有技巧,Vscode 里支持一种“Symbol 搜索”,Symbol 是什么呢? 对于代码,Symbol 可以理解为函数名字,这个功能可以方便的在一个大的代码工程里快速搜索某个函数。Vscode里把 Markdown 的 Heading(标题) 当做 Symbol,所以在 Vscode里 按 “Cmd + T”,也可以进入 Markdown 标题的模糊搜索,快速定位 Heading。相对于上面的“文件名模糊搜索”,“标题模糊搜索”提供了比文件级别更细粒度的检索。至于如何用好这个功能,这就要求我们在书写笔记的时候,对 Heading的命名用一些心思了,要“言之有物”。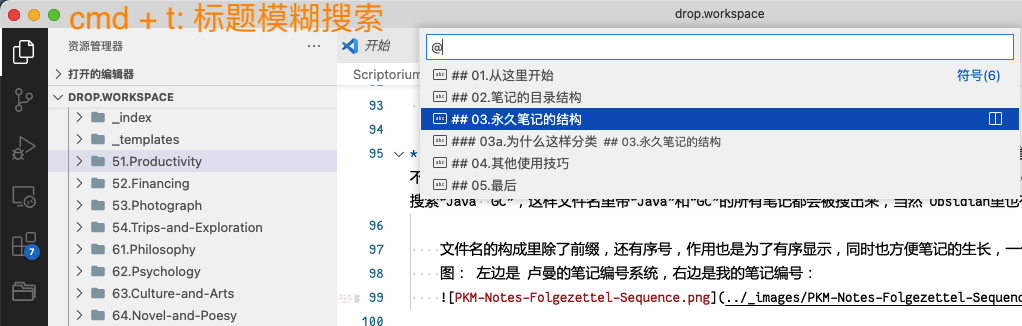
除了Vscode,像Atom、Sublime 等一众现代编辑器都有这个功能(标配),而 Obsidian 则需要通过插件 obsidian-switcher-plus11 来实现。
双链引用:笔记的引用我用Obsidian 提供的
[[ ]],Obsidian 默认是用 文件名作为链接名的,同时也提供对文件内的 Heading作为引用块,例如[[文件名.md#标题名]],如果修改文件名、或者拆分合并笔记,我就不用Vscode了,而是在 Obsidian里操作,让Obsidian 帮我自动更新引用。笔记建立引用要克制,只有「笔记A」真的需要引用到「笔记B」的时候才建立两篇笔记的连接,“必要时”才链接,这也符合笔记“自然生长”的概念。
本来网状结构也是一种 MOC(map of content),帮自己理清思路的,胡乱建立双链是在毁掉自己的笔记系统,就像无章法的标签体系——最后只能废弃。这不叫自然生长,这叫胡乱配对;标签:我不太用标签,也不强制标签的规则。但有个原则:如果通过文件夹已经是“明确的一个类别”,就不需要用这个类再建立标签了,这属于冗余信息。例如上面提到的,已经有了
Java文件夹,就没必要再建立“Java”标签了,但“Java”表示不了的子分类,例如 Java下面还有更细的子类别:JVM、ClassLoader等等,这些倒是可以建标签枢纽笔记:“除了索引表,卢曼还有另外一种非常重要的笔记:枢纽笔记(hub notes)12。枢纽笔记中列出了许多其他同属于某个主题的其他笔记”。说白了枢纽笔记就是一个索引,指向一组某主题的笔记。在 Obsidian 的 关系图谱里,枢纽笔记是一个中心化的节点,它本身没多少信息,只起一个索引的作用。但文件夹分类默认已经起到相同的作用了,每个文件夹下自然就是一个专题,所以对于这种情况就没必要建枢纽笔记,除非笔记跨了文件夹。
对于这类枢纽笔记,我都放在📂 _index文件夹中,在 Obsidian 的 关系图谱中,枢纽笔记向外的连线会很多,让整个图谱显得杂乱,这时候可以在图谱设置里排除掉这个📂 _index文件夹(语法-path:_index),让关系图谱清爽一些。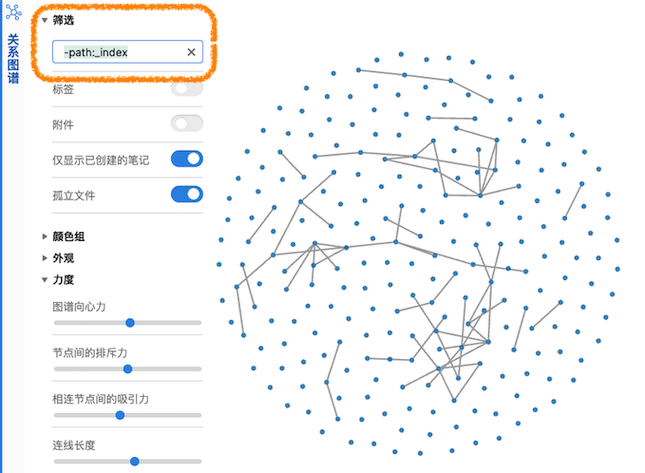
除了按“某个主题”索引的枢纽笔记,也可以有按“时间线”索引的枢纽笔记,可以方便的看“我这个月记了什么”,当然这种笔记也不是一定要有的,看自己需求,同样也是放在📂 _index文件夹;
至此,我的笔记体系的规则说完了,为什么要给自己的笔记格式立那么多规矩? 不累么…
无论树状结构、网状结构、或者标签体系,如果管理不好最终都变垃圾场。还记得当年第一个笔记 App里加过的标签吗? 现在看都不会再看一眼吧。
03a.为什么用这样的笔记结构
综上,我的永久笔记的结构是:“单层目录的矮树状结构,同时使用双链构成稀疏的网状”。
至于为什么用这样的结构,还是要从传统的树状结构 和最近时兴的网状结构比较说起。
03a1.网状结构 vs 树状结构
像 RoamResearch、Logseq 这些笔记似乎已经完全放弃了目录,完全采取完全平铺的方式,通过网状结构展示各个笔记的关系,在笔记系统中,网状结构的特点:
- 便于发现不同知识点的潜在联系,可以打破固有的树形概念结构,跨领域寻找联系;
- 创造和寻找灵感,发现新的研究方向;
- 劣势1,在树型层级中,我们很清楚知道两个节点表示上下级关系,但是在网状结构里,无法表示这种父子关系,仅仅知道二者“有关系”,这是纯网装结构在表达上的一种语义丢失。
Notion、OneNote、Evernote、Trilium依然采用传统的属性结构,不同的是 EverNote的“文件夹”就是个“真文件夹”,什么信息都不能存储,而 Notion 的无限层级结构里,每个节点都是可以存储信息的。除了笔记之外还有思维导图,也算是树状拓扑结构,总结一下树状结构的特点:
- 在学习过程中,树状层级有利于理清概念,通过层级关系,我知道概念A是上义或整体性概念,概念B则是下义或更细小的概念;
- 树状分类方便检索,树状的生长方向是单向的,总是从“更上层的父级概念” => “子概念”,这种单向也方便概念的回溯(相比较而言,网状的方向的可能性就太多了)
- 树状结构的劣势1,所有新建的笔记都要思考一个问题:我要把它放哪个概念层才更合理?尤其对于刚刚开始入门的领域,上来就思考怎么分类是本末倒置的,当对这个领域逐渐掌握和熟悉,自然会知道“它属于哪儿”
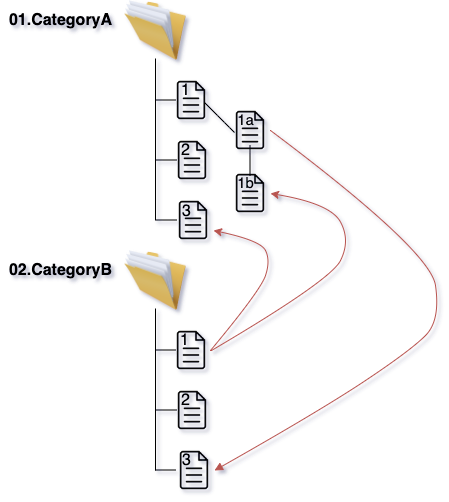
- 树形结构的劣势2:严格的树形目录无法表示“一个笔记同时属于多个主题文件夹”的情况,如下图,这样用引用可以解决:“笔记1a”还是在“类别1”下面,但从“类别2”到“笔记1a”建立一个引用

不好的例子1:过于繁杂的树形结构,笔记很容易被遗忘在很深的目录中(试想这种情况下,当我们回顾笔记的时候,需要一层层打开目录,也不知道下一层还有什么),另外“分类再分类”也是一种心智负担:
不好的例子2:这样的网状结构,不是有效的MOC(Map of Content),这是细菌培养皿:
03a2.结论是:两种结构我都要
树状结构便于检索和理清概念层级,很像我们理解知识的过程;
网状结构可以打破固有的层级结构,发现不同领域和层次知识间的联系,同时网状拓扑的建立也像新学习某个知识的过程。
这两种结构对于笔记体系都是有帮助的,所以都要。
同时通过上面不好的案例,我们发现,树状和网状的劣势都始于 用力过猛:比如过深的树状文件夹,比如迷宫一样的网状链接。所以,回到 03a这一章节的开始:我的永久笔记这部分的结构是 “单层目录的矮树状结构,同时使用双链构成稀疏的网状”
04.其他使用技巧
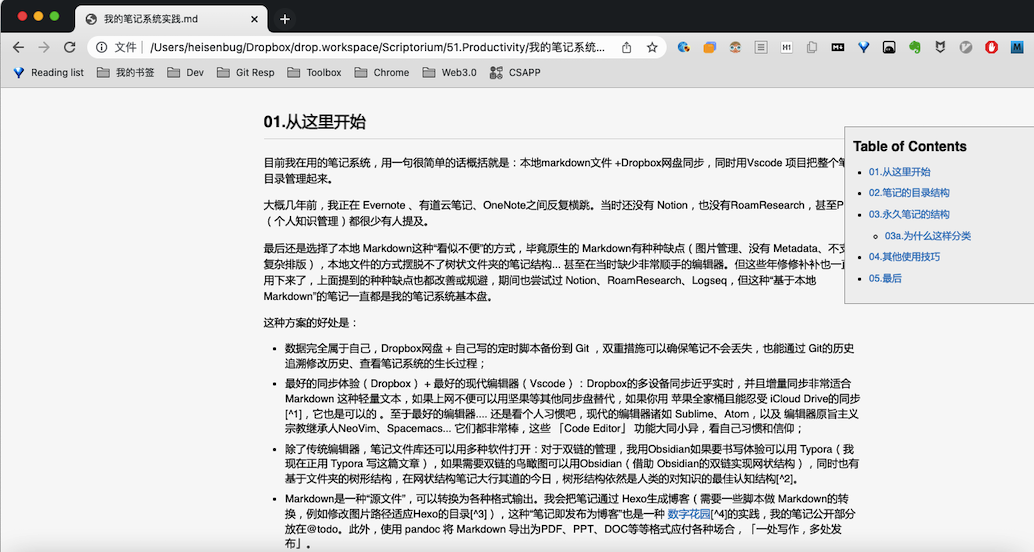
笔记除了书写,更多的使用场景是阅读,如果是在电脑上,我会用 Chrome 直接打开笔记目录,这里还需要一个 Chrome扩展:Markdown Preview Plus,可以把 Markdown 预览出来,支持多种主题。还支持 TOC 大纲,笔记的结构一目了然
笔记里我还会用一些“注解”,就是一些特殊语法,来帮助检索,比如如果我引用到了其他网页,会加
@ref标注一下,
例如@ref: [巧用分类法解决使用卡片笔记时遇到的困境](https://sspai.com/post/71274),
这样有什么好处呢,比如我想统计我的整个笔记库有多少网页引是来自sspai的文章,可以用 Shell命令行,在笔记根目录执行grep -irn "@ref" **/*.md | grep 'sspai' | wc -l: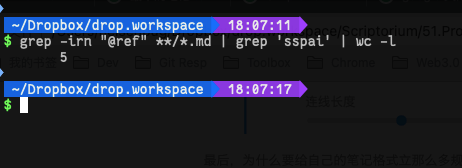
同样双链的
[[ ]]也可以这样搜索:egrep -irn "\\[\\[.+\\]\\]" **/*.md- 此外,我会用其他的注解,例如
@todo=待办,@toc=内容大纲,@tldr=笔记精要… 等等,这些注解都不是标准的 Markdown 语法,这样写只是为了让自己的笔记有统一的格式,以及检索方便,因为 Vscode 的搜索都是基于单行的。
05.最后
关于 #PKM (个人知识管理),这个话题很大也很难用几篇文章说清楚,个人的知识管理体系可能终生都在更新迭代。除了笔记还包括工作流、文献管理等等太多的话题,这里只写一点跟“笔记”相关的,抛砖引玉。
- 1.iCloud Drive的同步问题:如果发生了同步冲突,iCloud Drive的默认做法是存为一个快照,但并不通知用户发生了冲突,这会导致冲突的内容被吞掉了。对比 Dropbox的做法是生成一个“xxx的冲突版本”文件,提示让用户自己合并。显然 Dropbox的做法更适合做严格的文档同步器 ↩
- 2.MIT 认知科学家Joshua B. Tenenbaum 发表在PNAS 的论文中,比较了抽象知识的不同表征结构,如星形结构、聚类结构、环形结构等等,最终还是意识到人类的最佳知识结构是树形结构: The discovery of structural form | PNAS ↩
- 3.Hexo要求引用图片路径是绝对路径


- 4.什么是数字花园(Digital Garden)? - 知乎 对数字花园做了很好的诠释:“数字花园是介于笔记应用和博客应用之间的半公开数字展览馆,半公开指的不是读者没有权限阅览,而是很多想法只是相互关联的半成品,令他人难以轻易看懂。因为数字花园降低了对内容的要求,不强求作者将所有内容都打磨成文章级的成果,数字花园就会鼓励作者产出更多的内容,不拘一格降笔记”。 ↩
- 5.P.A.R.A. 四个字母分别代表 项目(Projects)— 领域(Areas) — 资源(Resources) — 档案(Archives) 四个顶级类别, 包括您在工作和生活中可能遇到的每种类型的信息。例如 Project类别的特点是有目标、有交付日期、会结束;Area 类别则是"需要一直负责和维护的活动领域",例如工作中需要持续关注的领域,或者打算持续发展兴趣(健康/写作/营销等)。Forte上的原文链接:The PARA Method: A Universal System for Organizing Digital Information - Forte Labs ↩
- 6.卢曼的文献笔记样例和使用: Luhmann’s Literatur Note Examples — Zettelkasten Forum ↩
- 7.卢曼提到卡片盒笔记是内增长的(internal growth):Communicating with Slip Boxes by Niklas Luhmann ↩
- 8.赫尔博斯说:“天堂是图书馆的模样”, 《缮写室》中说 “天堂是缮写室的模样” ,作者在外公那阴暗、并不宽绰的书房里遇到了各类文学作品。她将这里比喻为生命中的第一个缮写室(缮写室是欧洲中世纪制作书籍的场所) ↩
- 9.常青笔记 的概念来自Andy Matuschak的笔记: Evergreen notes ,Andy本人可能在Obsidian上发布了常青笔记,将上面的笔记转为了 Obsidian库:https://publish.obsidian.md/andymatuschak/Start+Here, 也可能是Anthony Gold获得授权后转置的 ↩
- 10.杜威十进制图书分类法百度百科 ↩
- 11.使用Obsidian 插件 switcher++实现 Vscode的符号搜索: 我给了快捷键 Cmd + R,呼出搜索框,直接是文件名模糊搜索, 输入
@触发当前文件内搜索Heading, 输入#触发全库内搜索Heading ↩ - 12.对卢曼的“枢纽笔记”的说明: The Money Is in the Hubs: Johannes Schmidt on Luhmann’s Zettelkasten • Zettelkasten Method ↩