内存寻址(Memory Addressing): 分段机制把 逻辑地址 转换为 线性地址, 分页机制进一步把该 线性地址 再转换为 物理地址.
段式内存管理
内存可寻址范围总是跟”地址总线宽度”和”寄存器宽度”相关
实模式的诞生(16位处理器及寻址)
- 在8086处理器诞生之前, 内存寻址方式就是直接访问物理地址. 8086处理器为了寻址1M的内存空间, 把地址总线扩展到了20位. 但是, 一个尴尬的问题出现了, ALU的宽度只有16位, 也就是说, ALU不能计算20位的地址. 为了解决这个问题, 分段机制被引入
- 为了支持分段, 8086处理器设置了四个段寄存器:CS, DS, SS, ES每个段寄存器都是16位的, 同时访问内存的指令中的地址也是16位的.
- 在送入地址总线之前(20位), 要将端寄存器(16位)的值与内存地址(16位, 即段内偏移值)相加
- 端寄存器的值左移4位, 低位补0, 然后加上内存地址
+-----------------+ |
保护模式的诞生(32位处理器及寻址)
- 80286处理器的地址总线为24位, 寻址空间达16M, 同时引入了保护模式(内存段的访问受到限制)
- 80386处理器是一个32位处理器, ALU和地址总线都是32位的, 寻址空间达 4G. 也就是说它可以不通过分段机制, 直接访问4G的内存空间. 但它必须支持实模式和保护模式. 所以, 80386在段寄存器的基础上构筑保护模式, 并且保留16位的段寄存器.
- 从80386之后的处理器, 架构基本相似, 统称为IA32(32 Bit Intel Architecture).
IA32的内存寻址机制
IA32的三种地址
- 逻辑地址: 每个逻辑地址都由一个”段的选择符”和”偏移量组成”. IA32中有六个16位段寄存器
- 线性地址:线性地址是一个32位的无符号整数, 可以表达高达2^32(4GB)的地址. 通常用16进制表示线性地址, 其取值范围为0x00000000~0xffffffff.
- 物理地址:也就是内存单元的实际地址, 用于芯片级内存单元寻址. 物理地址也由32位无符号整数表示.
MMU
MMU是一种硬件电路, 它包含两个部件, 一个是分段部件, 一个是分页部件, 在此, 我们把它们分别叫做分段机制和分页机制, 内存寻址分两个步骤:
分段机制把一个逻辑地址转换为线性地, 接着, 分页机制把一个线性地址转换为物理地址.
IA32的段寄存器
IA32中有六个段寄存器(16 bit):CS, DS, SS, ES, FS, GS.
跟8086的段寄存器不同的是, 这些寄存器存放的不再是某个段的基地址, 而是某个段的选择符(Selector).
IA32(硬件)分段机制的实现
段描述符
段是虚拟地址空间的基本单位, 段描述符 是一个8字节的数据结构, 包括以下几个属性:
- 段的界限(Limit):在虚拟地址空间中, 段内可以使用的最大偏移量.
- 段的基地址(Base Address):在线性地址空间中段的起始地址.
- 段的保护属性(Attribute):表示段的特性. 例如, 该段是否可被读出或写入, 或者该段是否作为一个程序来执行, 以及段的特权级等等.
上面的数据结构我们称为段描述符,多个段描述符组成的表称为段描述符表
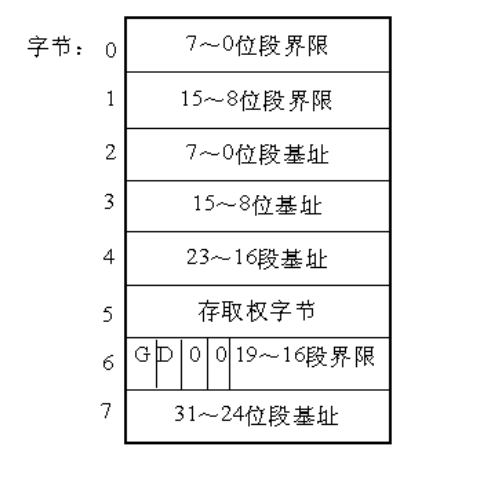
从图可以看出,一个段描述符指出了段的 32 位基地址和 20 位段界限(即段长)。这里我们只关注基地址和段界限,其他的属性略过。
段描述符表
描述符表(即段表)定义了IA32系统的所有段的情况. 所有的描述符表本身都占据一个字节为8的倍数的存储器空间, 空间大小在8个字节(至少含一个描述符)到64K字节(至多含8K)个描述符之间.
- 全局描述符表(GDT)
全局描述符表 GDT(Global Descriptor Table),除了任务门,中断门和陷阱门描述符外,包含着系统中所有任务都共用的那些段的描述符。它的第一个 8 字节位置没有使用。 - 中断描述符表 IDT(Interrupt Descriptor Table)
中断描述符表 IDT(Interrupt Descriptor Table),包含 256 个门描述符。IDT 中只能包含任务门、中断门和陷阱门描述符,虽然 IDT 表最长也可以为 64 K 字节,但只能存取 2 K 字节以内的描述符,即 256 个描述符,这个数字是为了和 8086保持兼容。 - 局部描述符表(LDT)
局部描述符表 LDT(local Descriptor Table),包含了与一个给定任务有关的描述符,每个任务各自有一个的 LDT。有了 LDT,就可以使给定任务的代码、数据与别的任务相隔离。每一个任务的局部描述符表 LDT 本身也用一个描述符来表示,称为 LDT 描述符,它包含了有关局部描述符表的信息,被放在全局描述符表 GDT 中。
总结
IA32的内存寻址机制完成从逻辑地址–线性地址–物理地址的转换. 其中, 逻辑地址的段寄存器中的值提供段描述符, 然后从段描述符中得到段基址和段界限, 然后加上逻辑地址的偏移量, 就得到了线性地址, 线性地址通过分页机制得到物理地址.
首先, 我们要明确, 分段机制是IA32提供的寻址方式, 这是硬件层面的. 就是说, 不管你是windows还是linux, 只要使用IA32的CPU访问内存, 都要经过MMU的转换流程才能得到物理地址, 也就是说必须经过逻辑地址–线性地址–物理地址的转换.
Linux系统(软件)分段机制的实现
Linux基本不使用分段的机制, 或者说, Linux中的分段机制只是为了兼容IA32的硬件而设计的.
在 IA32 上任意给出的地址都是一个虚拟地址, 即任意一个地址都是通过选择符:偏移量的方式给出的, 这是段机制存访问模式的基本特点.
所以在IA32上设计操作系统时无法回避使用段机制. 一个虚拟地址最终会通过段基地址+偏移量的方式转化为一个线性地址.
但是, 由于绝大多数硬件平台都不支持段机制, 只支持分页机制, 所以为了让 Linux 具有更好的可移植性, 我们需要去掉段机制而只使用分页机制. 但不幸的是, IA32规定段机制是不可禁止的, 因此不可能绕过它直接给出线性地址空间的地址.
万般无奈之下, Linux的设计人员干脆让段的基地址为0, 而段的界限为4GB, 这时任意给出一个偏移量, 则等式为0+偏移量=线性地址, 也就是说“偏移量=线性地址”. 另外由于段机制规定“偏移量<4GB”, 所以偏移量的范围为0H~FFFFFFFFH, 这恰好是线性地址空间范围, 也就是说虚拟地址直接映射到了线性地址, 我们以后所提到的虚拟地址和线性地址指的也就是同一地址. 看来, Linux在没有回避段机制的情况下巧妙地把段机制给绕过去了.
特权等级(CPU Rings)和分段机制
由于IA32段机制还规定, 必须为代码段和数据段创建不同的段, 所以Linux必须为代码段和数据段分别创建一个基地址为0, 段界限为4GB的段描述符.
不仅如此, 由于Linux内核运行在特权级0, 而用户程序运行在特权级别3, 根据IA32段保护机制规定, 特权级3的程序是无法访问特权级为0的段的,
所以Linux必须为内核用户程序分别创建其代码段和数据段. 这就意味着Linux 必须创建4个段描述符: 特权级0的代码段和数据段, 特权级3的代码段和数据段
存疑: 在Ring0和Ring3的, 相同的的逻辑地址, 是对应不同的线性地址 [?]
@ref 参考: Linux内存寻址之分段机制 | ShareHub
页式内存管理
硬件分页
- 分页机制在段机制之后进行, 以完成线性—物理地址的转换过程. 段机制把逻辑地址转换为线性地址, 分页机制进一步把该线性地址再转换为物理地址.
- 分页机制管理的对象是固定大小的存储块, 称之为页(page). 分页机制把整个线性地址空间及整个物理地址空间都看成由页组成, 在线性地址空间中的任何一页, 可以映射为物理地址空间中的任何一页, 我们把物理空间中的一页叫做 页框(page frame)
- 80386使用4K(0xFFF)字节大小的页. 每一页都有4K字节长, 并在4K字节的边界上对齐(即每一页的起始地址都能被4K整除). 因此, 80386把最大可寻址4G字节的线性地址空间划分为1M个Page
线性地址的page, 与物理地址的page是多对一的关系, 也就是两个不同线性地址页, 可能指向同一个物理地址页
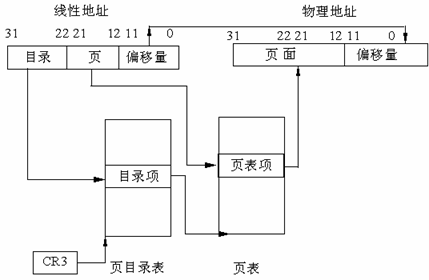
两级分页
为什么使用两级页表:
假设每个进程都占用了 4 G 的线性地址空间,页表共含 1 M 个表项,每个表项占 4 个字节,那么每个进程的页表要占据 4 M 的内存空间。为了节省页表占用的空间,我们使用两级页表。每个进程都会被分配一个页目录,但是只有被实际使用页表才会被分配到内存里面。一级页表需要一次分配所有页表空间,两级页表则可以在需要的时候再分配页表空间。
两级页表结构:
- 页目录(Page Directory): 两级表结构的第一级称为页目录,存储在一个 4 K 字节的页面中。页目录表共有 1 K 个表项,每个表项为 4 个字节,并指向第二级表。线性地址的最高 10 位(即位 31~位 32)用来产生第一级的索引,由索引得到的表项中,指定并选择了 1 K 个二级表中的一个表。
- 页表(Page Table): 两级表结构的第二级称为页表,也刚好存储在一个 4 K 字节的页面中,包含 1 K 个字节的表项,每个表项包含一个页的物理基地址。第二级页表由线性地址的中间 10 位(即位 21~位 12)进行索引,以获得包含页的物理地址的页表项,这个物理地址的高 20 位与线性地址的低 12 位形成了最后的物理地址,也就是页转化过程输出的物理地址。
Linux 中的分页机制
Linux 使用了一个适合 32 位和 64 位系统的分页机制。把二级分页机制中的”目录项”分三部分:页全局目录、
页顶级目录、页中间目录,加上页表,以及每个页表项指向的页框,分为 5 级。
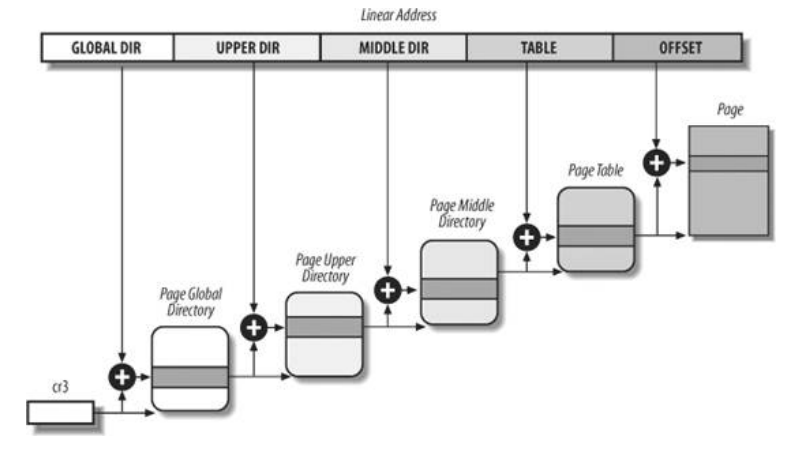
对于没有启用物理地址扩展的 32 位系统,两级页表已经足够了。从本质上说 Linux 通过使“页上级目录”位和“页中间目录”位全为 0,彻底取消了页上级目录和页中间目录字段。不过,页上级目录和页中间目录在指针序列中的位置被保留,以便同样的代码在 32 位系统和 64 位系统下都能使用。内核为页上级目录和页中间目录保留了一个位置,这是通过把它们的页目录项数设置为 1,并把这两个目录项映射到页全局目录的一个合适的目录项而实现的。
启用了物理地址扩展的 32 位系统使用了三级页表。Linux 的页全局目录对应 80×86 的页目录指针表(PDPT),取消了页上级目录,页中间目录对应 80×86 的页目录,Linux 的页表对应 80×86 的页表。
最后,64 位系统使用三级还是四级分页取决于硬件对线性地址的位的划分。
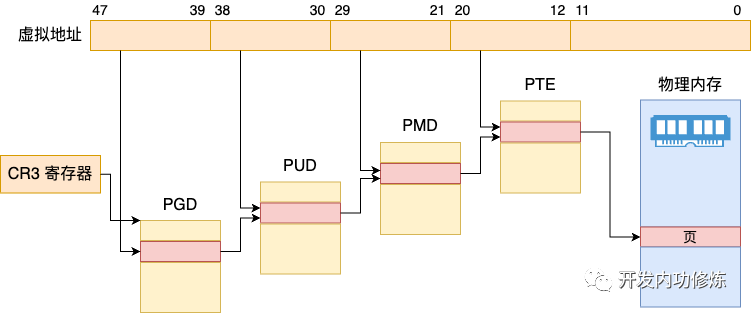
无论是32 or 64 位 Linux 系统,虚拟内存线性地址都可以看做 “n 位页号 + 12位页内偏移”,通过页号来管理一个个 2^12大小的页(所以内存页 size = 4k)
64 位 Linux 4 级分页:
- 一级页表(47-39):Page Global Dir,简称 PGD
- 二级页表(38-30):Page Upper Dir,简称 PUD
- 三级页表(29-21):Page Mid Dir,简称 PMD
- 四级页表(20-12):Page Table,简称 PTE
页帧 & 页框
四级页表(PTE)里每一项,都指向一个4K大小的内存页,内存页在不同语境翻译可能不一样:页框/ 页帧/ page frame
- 内存页:可能更偏向于虚拟内存里的最小单位;
- 页框 / 页帧/ page frame:倾向于描述物理内存的最小单位;
对于这个4K大小的单位(无论是虚拟内存层面 or 物理内存层面),Linux 内核中使用 struct page表示
区分缓冲IO里的 “page cache”
TLB
存储计算值的高速缓存称为 Translation Look-Aside Buffer(TLB)。它通常是一个小缓存,但是它必须非常快。如果 TLB 查找未命中,处理器必须执行页表遍历;这可能相当昂贵。每个程序员都应该了解的内存知识4 - 虚拟内存