➤ 从硬件角度说明为什么需要内存对齐

内存条上的黑色颗粒,被称为 Chip,每个 Chip 内部又是由 8 个 Bank 组成;

每个 Bank 可以看做是一个矩阵,矩阵上每个元素可以存储1字节(8bit,也就是说包含了8个小电容)
对于我们在应用程序中内存中地址连续的8个字节,例如0x0000-0x0007,是从位于 bank 上的呢?直观感觉,应该是在第一个 bank 上吗?其实不是的,程序员视角看起来连续的地址0x0000-0x0007,实际上是位于8个 bank 中的,每一个 bank 只保存了一个字节。在物理上,他们并不连续。下图很好地阐述了实际情况,一个 64 bits 连续的空间,对应到每个 Bank 上的一个元素(8 bits):
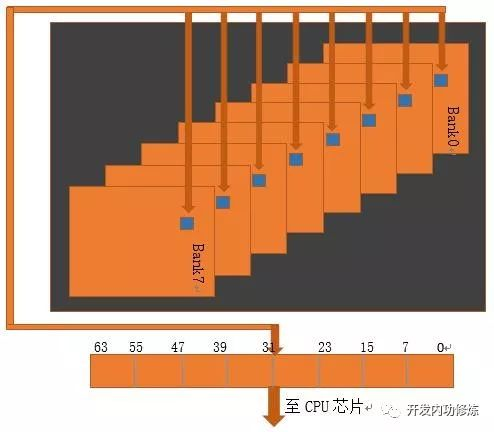
这样设计的原因是电路工作效率。内存中的8个 bank 是可以并行工作的。上面的例子中读取 8 字节,只需要 1 个周期,如果设计为连续地址存储在一个 bank 里,只能串行进行读取,需要读8次,这样速度会慢很多。
所以,内存对齐最最底层的原因是内存的 IO 是以8个字节64bit 为单位进行的。对于64位数据宽度的内存,假如 cpu 也是64位的 cpu(现在的计算机基本都是这样的),每次内存 IO 获取数据都是从同行同列的8个 bank 中各自读取一个字节拼起来的。从内存的0地址开始,0-7字节的数据可以一次 IO 读取出来,8-15字节的数据也可以一次读取出来。
换个例子,假如你指定要获取的是0x0001-0x0008,也是8字节,但是不是0开头的,内存需要怎么工作呢?没有好办法,内存只好先工作一次把0x0000-0x0007取出来,然后再把0x0008-0x0015取出来,把两次的结果都返回给你。CPU和内存IO的硬件限制导致没办法一次跨在两个数据宽度中间进行IO。
事实上,编译和链接器会自动替开发者对齐内存的,尽量帮你保证一个变量不跨列寻址。但是他不能做到十分完美。
CPU 缓存的最小单元是 Cache Line,size 是 64 字节,可以整除 8 字节(内存的 IO 单位)
当数据存储在成倍数据大小的地址中时,CPU 会更有效地读取和写入内存。例如,如果数据存储在倍数为 4 的地址中,则会更有效地访问 4 字节整数。如果数据未对齐,则 CPU 需要执行更多地址计算工作来访问数据。
默认情况下,编译器会根据数据的大小对齐数据:char 在 1 字节的边界上对齐,short 在 2 字节的边界上对齐,int、long 和 float 在 4 字节的边界上对齐,double 在 8 字节的边界上对齐,依次类推。
通常,无需担心对齐方式。编译器通常在基于目标处理器和数据大小的自然边界上对齐数据。在 32 位处理器上,数据最多在 4 字节的边界上对齐,在 64 位处理器上,数据最多在 8 字节的边界对齐。但是,在某些情况下,你可以通过指定数据结构的自定义对齐方式获得性能提升或节约内存。
另外,通过将常用数据与处理器的缓存行大小对齐,可以提高缓存性能。例如,假设定义了一个大小小于 32 个字节的结构。可能需要使用 32 字节对齐方式,以确保有效缓存结构的所有实例。
使用 C 11 关键字 _Alignof 来获取类型或变量的首选对齐方式。
@ref: 对齐 (C11) | Microsoft Learn
对于 C/C++中的基本数据类型,假设它的长度为 n 字节,那么该类型的变量会被编译器默认分配到 n 字节对齐的内存上。
例如,char 的长度是 1 字节,char 类型变量的地址将是 1 字节对齐的(任意值均可);int 的长度是 4 字节,所以 int 类型变量将被分配到 4 字节对齐的地址上。这种默认情况下的变量对齐方式又称作自然对齐(naturally aligned)
What is natural alignment? Why should a generic pointer be aligned? - Quora
struct 以及含位域的结构体对齐 => C-Tutorials.01.基础
因为 RISC CPU 的设计,大多精简指令集的指令长就是字长。而指令还需区分取立即数和各种 action, 一字长的指令无法全部用来表示地址空间。综上,大多 RISC CPU 强制地址对齐,地址的低位补成 0。顺便也减少了地址线的宽度。
基于此,一般的 RISC CPU 的地址线宽度为 $wordSize - log_2\frac{wordSize}{byteSize}$.
比如一个 32 位 CPU 的字长是 32 bit, 字节大小为 8 bit, 那么地址线宽度为 $32 - log_2\frac{32}{8} = 30$ ,可选择 2^30 个地址单位,每个单位的大小是 4 字节,于是总共可管理 2^{30+2} 字节的内存。这也是逻辑地址最低位总是为 0 的来历了(对于 32 bit 字长的 CPU, 逻辑地址的最低 2 位为 0)
CPU 总是以 word size (32 位上 = 4)为单位从内存中读取数据,对于没有对齐的数据,例如在4 字节的 RISC CPU 上,读一个未对齐的 int,需要读两次 word size 的数据
@ref: 如何理解 struct 的内存对齐? - 張道遠 的回答 - 知乎
@ref: 对内存对齐的深一步理解_12935177的技术博客_51CTO博客
ARM CPU 有以下几条指令:
- LDR/STR: address must be 4-byte aligned
- LDRH/STRH: address must be 2-byte aligned // H=Half
- LDRB/STRB: address must be byte aligned // B = Byte
reinterpret_cast<int*> ptr 将调用 LDR, 但如果 ptr 不是 4 字节对齐,则会报错。
例如:
char *buffer[1024]; // 假设buff地址是0x0000,0000 |
从 buff+1 取 4 字节,正确做法是 memcpy: memcpy(&i, buffer+1, 4),memcpy 是如何实现的?
memcpy (ARM 平台的实现)先检测是 dst 地址否 4 字节对齐,如果是,则直接 LDR 逐 4 字节读取,如果没有对齐,则先用 LDRB 逐字节读取,到对齐后再 LDR
面试题场景的手写 memcpy 实现(通常没有用到逐 word 拷贝,而是用 char* 逐 byte 拷贝)
// 链接:https://www.nowcoder.com/questionTerminal/9602083ec8d749999d86adf8a725b4f7 |