正则表达式的流派
正则的两个标准: Perl 和 POSIX 标准
- Perl标准(PCRE): 标准概述: perlre - perldoc.perl.org,只关注[The Basics] 和[Metacharacters] (元字符)这两节即可.
- 正则表达式在线检测: Debuggex
- Posix标准,包括两个流派:BRE(基本型正则表达式)和ERE(扩展型正则表达式)
- BRE: grep,sed,vi
- ERE: egrep,awk,grep -E,
Perl正则
位置
^表示行首,例如 ^abc 表示abc号开头的行; 或者不匹配 [^abc] 任意不是abc的
$表示行尾,例如 333$ 表示已字符"333"结束的行;
次数
* 星号表示出现0次或N次,相当于{0,},比如\$*b可以匹配"b"或者"$$$b";
? 表示出现0次~1次,相当于{0,1}
+ 表示出现大于等于1次,相当于{1,}
. 点号表示任何单个字符,换行符(\n)除外,点号可以与上面的次数符号组合,比如.*表示任何字符或没有字符
.*与.*?区别: 前者是贪婪匹配(greedy),后者是非贪婪匹配(lazy)
字符簇
例如 [AaEeIiOoUu] 表示一个表示所有元音字符的字符簇
[a-z] // 匹配所有的小写字母
[a-zA-Z] // 匹配所有的字母
[0-9\.\-] // 匹配所有的数字,句号和减号
注意: 前面曾经提到^表示字符串的开头,但它在字符簇里使用时,它表示"非"或"排除"的意思,[^0-9]指非数字
分组和其他
小括号()表示分组, 例如 gr(a|e)y 匹配 "gray" 和 "grey", (A\d){2} 匹配 "A数字A数字";
中括号[]表示匹配其中一个字符,例如 [Aa]匹配A或a,[3A-Z]匹配3或A~Z; [1-3a-f] 匹配1~3或a~f任意一个字符,[^0-9]表示非数字.
大括号{m}表示出现m次,例如a{3}表示aaa,{n,m} 表示最少n次,最多m次;
A|B 表示可能匹配A表达式或B表达式
字符类型 & 特殊转义字符
\w表示一个字母或数字,相当于[a-zA-Z|0-9]
\W表示非一个字符或数字
\b表示一个单词,位于\w和\W之间的东西
\d表示数字,相当于[0-9]
\D表示非数字,相当于[^0-9]
\s表示空格
\S表示非空格
\l表示小写字符,\u表示大写字符
\L表示非小写字符,\U表示非大写字符
\n 换行符
\t 制表符
POSIX正则
Posix正则标准分为BRE和ERE,vi/grep/sed属于前者,awk属于后者,BRE与Perlb正则标准(PCRE)相差的更多一点,ERE与Perl标准相差比较小.
这里只记住几个例子就可以:
vi/grep/sed中的正则:
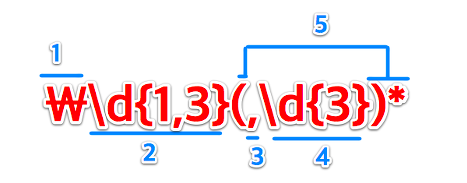
[0-9]\{1,3\} 表示数字0-9出现1-3次,注意 表示次数的大括号要转义,这点与Perl标准不同
^[0-9]\+ 表示数字至少出现一次,注意 这里的+号要加转义符 (星号,问号这些表示数量的符号,在POSIX也要转义)
^[0-9].*[a-z]$ 表示数字开头并且小写字母结尾
\<ngx 表示ngx开头的单词,注意 perl里没有\<的语法
arg\> 表示arg结尾的单词,注意 perl里没有\>的语法
\(int\|char\) 表示匹配"int"或"char"字符串,等效于perl标准的(int|char),posix标准里的左右括号和|都要加转义
注: 上面用
[]中括号括起来的叫字符簇,参考 [[#字符簇]]
从上面的几个例子可以看出,posix标准比perl标准的语法更繁琐,posix正则标准里的()|{}这些符号前要加转义符(吐槽下,这也是为什么POSIX正则不如Perl流行的原因吧),
例如: 在vim里想用^[0-9]+搜索数字开头是搜不出来的,因为+号前面要加转义.
Java中的正则表达式
Java的正则语法与Perl标准基本一致,参考Pattern (Java Platform SE 7 )
转义符
- 常见的有
\n,\t,\",\\,这些转义字符占1Char; - “ab\n”.length()返回3;
- java字面表达式的写法和”编译器看到的”不一样,
a\\b在Java编译器看来是”a\b”;
用Java字符串来写正则表达式,需要注意的转义符的使用:
- 如果要匹配点,中小括号,星号等等,正则要加双转义符,
\\.匹配点\\[匹配左中括号 - 如果要匹配斜杠,要写成四个转义符
\\\\
String s1 = "a\\b"; // 实际字符串是'a\b', |
@ref 理解 Java 正则表达式怪异的 \ 和 \\,让您见怪不怪
Pattern & Matcher
Pattern p=Pattern.compile("\\d+"); |
public static String maskEmoji(String str) { |
Pattern捕获组
Pattern用小括号包含的部分叫一个捕获组:
String source = "http://a.changyan.com/api/2/config/get/cy7hcbyIb?callback=383768658"; |
捕获组可以递归的使用,比如:
String reg = "((A)(B(C)))"; // 包括4个捕获组, |
appendReplacement
- matcher.find();
- matcher.appendReplacement(stringBuff,”xxx”); // 把当前匹配替换为param2,并append到param1字符串后面.
常用正则
测试地址 Debuggex: Online visual regex tester. JavaScript,Python,and PCRE.
数字: ^\d*$ |