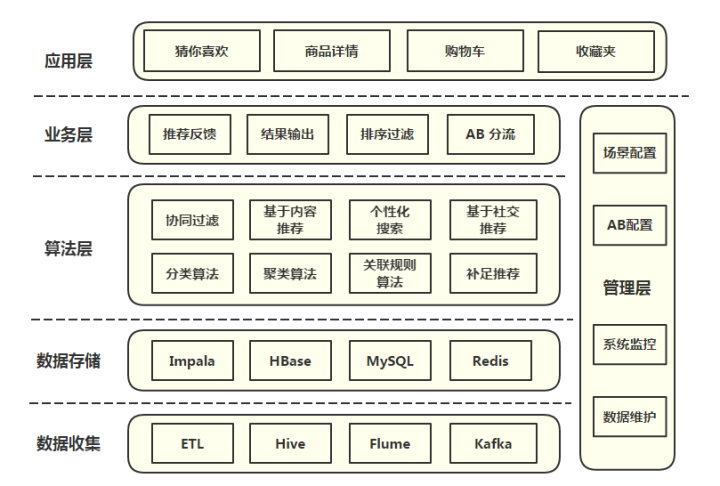
系统架构
效果评估
先了解一个概念: 混淆矩阵
混淆矩阵是用来总结一个分类器结果的矩阵。对于k元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。
对于最常见的二元分类来说,它的混淆矩阵是2乘2的,如下

命名规则: 真实-预测
TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
一般来说, 推荐效果的指标有:
- 准确率(Precision)和召回率(Recall)
设R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。
对用户u推荐N个物品(记为R(u)),令用户u在测试集上喜欢的物品集合为T(u),然后可以通过准确率/召回率评测推荐算法的精度: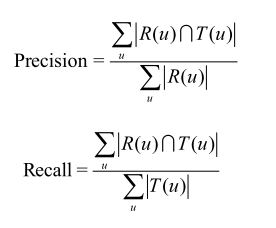
- F-score/F-measure
这是一种同时考虑准确率和召回率的指标。公式如下:
可以看出F的取值范围从0到1。另外还有一种F的变体如下所示:
常用的两种设置是和,前者中recall重要程度是precision的两倍,后者则相反,precision重要程度是recall的两倍。 - CTR(点击率): CTR(Click-Through-Rate)即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content)。
- CVR(转化率): CVR (Conversion Rate)即转化率。是一个衡量CPA广告效果的指标,简言之就是用户点击广告到成为一个有效激活或者注册甚至付费用户的转化率。
CVR=(转化量/点击量)*100% - 停留时间(Duration)
推荐算法
推荐算法大致可以分为以下几类:
①基于流行度的算法: 简单粗暴,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
②协同过滤算法(Collaborative Filtering, CF):
- Memory-based推荐:这两种方法都是将用户的所有数据读入到内存中进行运算的,因此成为Memory-based Collaborative Filtering。
Memory-based推荐方法通过执行最近邻搜索,把每一个Item或者User看成一个向量,计算其他所有Item或者User与它的相似度。有了Item或者User之间的两两相似度之后,就可以进行预测与推荐了。
CF算法简单原理是User喜欢那些具有相似兴趣的Users喜欢过的Items。包括:- Item-based方法:基于用户的协同过滤算法(user-based collaboratIve filtering);
- User-based方法:基于Item的协同过滤算法(item-based collaborative filtering);
- Model-based推荐(Model-based collaborative filtering)包括Aspect Model,pLSA,LDA,聚类,SVD,Matrix Factorization等,这种方法训练过程比较长,但是训练完成后,推荐过程比较快。
- Model-based推荐最常见的方法为Matrix factorization.
- 矩阵分解通过把原始的评分矩阵R分解为两个矩阵相乘,并且只考虑有评分的值,训练时不考虑missing项的值。R矩阵分解成为U与V两个矩阵后,评分矩阵R中missing的值就可以通过U矩阵中的某列和V矩阵的某行相乘得到
- 矩阵分解的目标函数: U矩阵与V矩阵的可以通过梯度下降(gradient descent)算法求得,通过交替更新u与v多次迭代收敛之后可求出U与V。
- 矩阵分解背后的核心思想,找到两个矩阵,它们相乘之后得到的那个矩阵的值,与评分矩阵R中有值的位置中的值尽可能接近。这样一来,分解出来的两个矩阵相乘就尽可能还原了评分矩阵R,因为有值的地方,值都相差得尽可能地小,那么missing的值通过这样的方式计算得到,比较符合趋势。
- Memory-based推荐:这两种方法都是将用户的所有数据读入到内存中进行运算的,因此成为Memory-based Collaborative Filtering。
协同过滤中主要存在如下两个问题:稀疏性与冷启动问题。已有的方案通常会通过引入多个不同的数据源或者辅助信息(Side information)来解决这些问题,
用户的Side information可以是用户的基本个人信息、用户画像信息等,
而Item的Side information可以是物品的content信息等。
③基于内容的算法: 推荐用户有兴趣的Item在内容上类似的Item。利用word2vec一类工具,可以将文本的关键词聚类,然后根据topic将文本向量化。
这种方法可以避免Item的冷启动问题(冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是基于内容的推荐算法可以分析Item之间的关系,实现推荐),
弊端在于推荐的Item可能会重复,典型的就是新闻推荐④基于模型的算法: LR, FM, DNN, CNN, RNN
- 逻辑回归(Logistic Regression)是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛。
- 因子分解机(Factorization Machine) 以下简称FM,是由Steffen Rendle在2010年提出的,模型主要通过特征组合来解决大规模稀疏数据的分类问题。
- 基于卷积神经网络(CNN)的推荐系统:此种系统中的卷积神经网络大多是用于特征提取(feature extraction)的;
- 基于循环神经网络(RNN)的推荐系统:循环神经网络特别适用于处理推荐系统中的评级和序列特征的时序动态;
- 基于深度语义相似性模型(Deep Semantic Similarity Model)的推荐系统:深度语义相似性模型(DSSM)是一种广泛应用于信息检索领域的深度神经网络。它非常适用于排行榜(top-n)推荐。基础型DSSM由MLP组成,更高级的神经层比如卷积层和最大池化(max-pooling)层可以被很容易地添加进去;
上面的FM, FFM, Deep FM都是基于CTR预估算法的
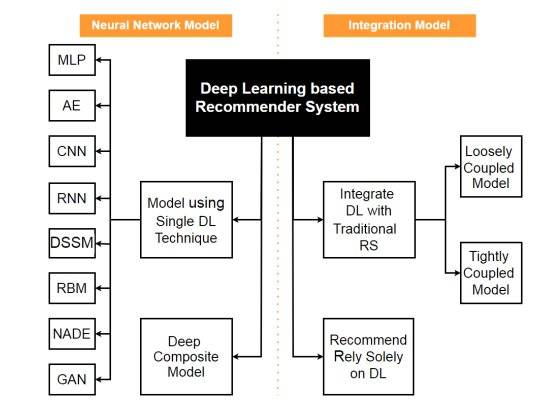
下图总结了基于深度学习的推荐系统分类的二维体系,左侧部分对神经网络模型进行了说明,右侧部分则说明了整合模型。
⑤基于知识的推荐(Knowledge-based Recommendation)在某种程度是可以看成是一种推理(Inference)技术,它不是建立在用户需要和偏好基础上推荐的。
基于知识的方法因它们所用的功能知识不同而有明显区别。
效用知识(Functional Knowledge)是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,
所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。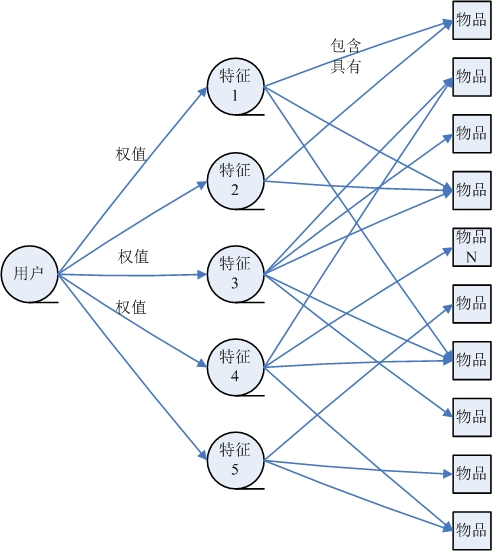
召回
召回(recall): 推荐系统往往只推荐有限个(如k个)物品给某个用户。真正相匹配的物品我们称之为 相关物品 (也就是二元分类中的阳性)。
- 召回率(recall) = 所推荐的k个物品中相关物品的个数 ÷ 所有相关物品的个数
- 精度(precision) = 所推荐的k个物品中相关物品的个数 ÷ k
比如说,根据你的喜好我们推荐了10个商品,其中真正相关的是5个商品。在所有商品当中,相关的商品一共有20个,那么:
召回率 = 5 / 20
精度 = 5 / 10
附录
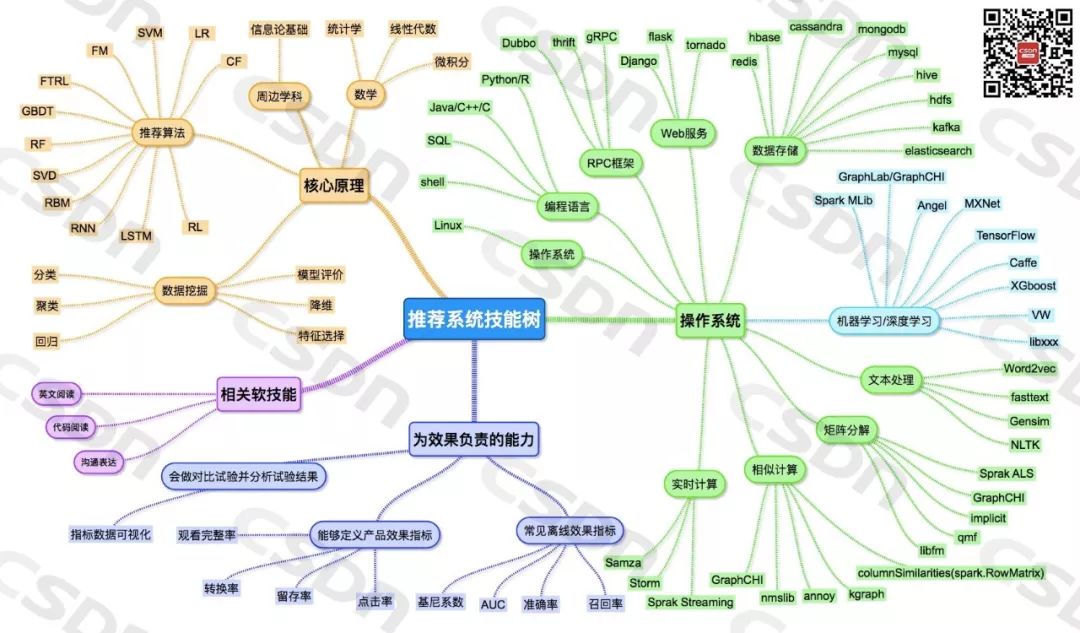
推荐系统技能树: