什么是Spark
概述
现如今在大规模数据处理分析的技术领域中,Hadoop及其生态内的各功能组件占据了绝对的统治地位。
Hadoop原生的MapReduce计算框架由于任务抽象简单、计算流程固定、计算的中间结果写入磁盘引起大量读写开销等短板,正逐步的被基于内存的分布式计算框架Spark代替,应用于各类大规模数据处理分析的场景中,其优势主要体现在以下5个方面:
- 1、更快的计算速度。采用计算中间结果的内存缓存机制和基于DAG的数据处理过程优化策略,进一步提升数据处理速率。
- 2、简单易用的分布式计算。将大规模数据处理任务,抽象为RDD的处理变换操作,将并行实现的分布式计算任务拆分为各自独立的串行计算过程。
- 3、适合丰富的应用场景。Spark内部集成了SQL、机器学习、流计算、图运算等多种类型计算模型,满足多种大规模数据分析的场景需求。
- 4、兼容多样的存储系统。满足对包括HDFS、HBase、Hive、S3等多种大规模数据存储系统的高效读写需求,轻松处理TB级以上规模以上的数据。
- 5、资源管理与高可靠性。结合Yarn、Mesos等多种类型的资源管理器,监控协调各计算子任务的运行状态,失败重启机制确保分布式作业的可靠性。
RDD计算模型原理
Spark将数据处理过程抽象为对内存中RDD(弹性分布式数据集)的操作,RDD的可以通过从数据源直接读取和集合数据类型封装两种方式创建。
针对RDD的操作,根据其结果主要分为如map、flatMap、mapPartition、filter等生成新的RDD的transformation(转换)操作和collect、reduce、foreach等生成集合数据类型或结果写入的action(行为)操作两大类。
下图描述了一个典型的Spark作业基于RDD实现数据的处理过程。其中,Spark对RDD的处理过程是惰性的,只有调用对RDD的action操作才能启动对RDD的计算过程,连续的调用多个transformation操作是无法使数据处理过程真正的执行。
在触发RDD计算过程后,根据Spark内置的DAG(有向无环图)引擎将多个对RDD的操作执行策略进行优化。
为满足对大规模数据的处理需要,Spark将RDD划分为多个partition(分区),以partition为单位将数据分散到集群上的各个节点中。
针对RDD的action操作和transformation操作间的本质区别就是生成的结果是否为RDD。

基于Yarn实现资源管理
由于Hadoop的HDFS与Spark的RDD抽象读写具有较为完备的兼容性,各版本Spark均提供对应当前Hadoop版本的安装包。
同样,Spark也可以使用Hadoop中的Yarn作为自身的资源管理器,用以完成对Spark集群中是作业管理和任务计算资源调度分配等工作。
在Spark作业的执行过程中,Yarn将在集群中的物理节点上的Executor的JVM进程封装为独立的Container,并提供独立的临时文件目录以及内存和CPU资源。
同时,Spark还提供了共享文件依赖的机制将Spark作业执行过程中,各Executor所需的如jar包、.so动态库、py文件及其他格式类型的文件依赖资源与Spark作业自身的执行文件分发到各Container中,使得Spark作业能够具备更为灵活的拓展性。

技术栈
现如今,Spark作业支持Java、Scala、Python以及R四种语言编写,Spark自身提供了SQL、机器学习、流计算以及图运算四种类型的计算功能组件,开发人员可根据实际的应用需求和相应组件的功能特性完成Spark作业的开发。
但是,其中如GraphX等部分功能组件仅支持Java及Scala语言的调用。
核心组件
核心组件如下: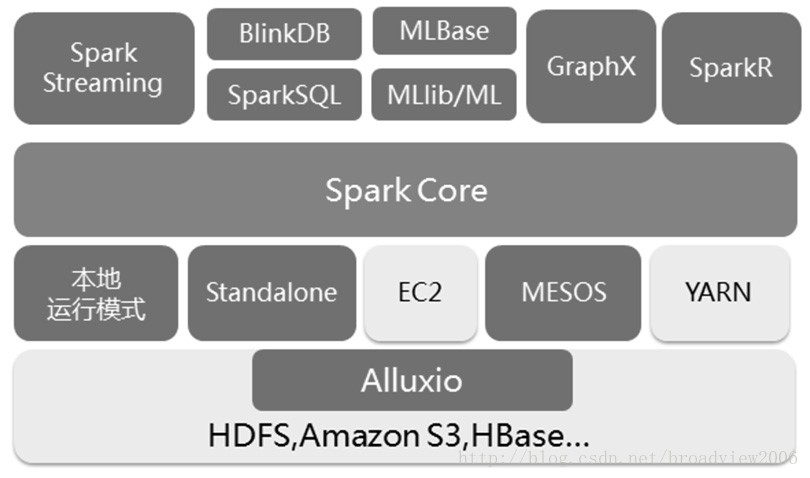
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
基于对内存中RDD操作和DAG引擎优化,Spark能够实现比基于原生MapReduce的Hive SQL更高效的计算过程。同时,采用DataFrame封装Spark作业能够以函数调用的方式完成SQL操作。 - MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,
比如分类、回归等需要对大量数据集进行迭代的操作。之前可选的大数据机器学习库Mahout,将会转到Spark并在未来实现。 - Spark Streaming:允许对实时数据流进行处理和控制。很多实时数据库(如Apache Store)可以处理实时数据。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
Spark Streaming将数据源抽象为DStream,将各时间窗内持续产生的实时数据切分为不同的RDD,以RDD为单位完成对时间窗内实时数据的处理,但其计算模式仍存在批处理的特性。 - GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
Spark中自带的图运算引擎GraphX采用由并行超步与全局同步组成的Bulk Synchronous Parallell(整体同步并行)模式,将图运算过程抽象为各步的迭代直至符合收敛停止条件。