LSM-Tree 概览
➤ What’s LSM-Tree: Log Structured Merge Trees(LSM)
➤ Google BigTable → LSM-Tree
@ref: 全面了解大数据“三驾马车”的开源实现_InfoQ精选文章
作为 Google 的大数据三架马车之一,Bigtable 依托于 Google 的 GFS、Chubby 及 SSTable 而诞生,用于解决 Google 内部不同产品在对数据存储的容量和响应时延需求的差异化,力求在确保能够容纳大量数据的同时减少数据的查询耗时。
论文中很多很酷的方面之一就是它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree。
@ref: Bigtable: A Distributed Storage System for Structured Data - OSDI ‘06 Paper
在BigTable里, SSTable(Sorted Strings Table)是一个基本的单元。每个Tablet有若干个SSTable。论文里面并没有提到SSTable是怎么样实现的。但是根据对开源的LevelDB的代码,可以看出SSTable是LSM-Tree的一种实现。
论文→ [Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth (Betty) O’Neil, “The Log-Structured Merge-Tree,” patent granted to Digital Equipment Corporation, December 1993; appeared in ActaInformatica 33, pp. 351-385, June 1996].
➤ LSM-Tree vs B+Tree
传统数据库使用 B-Tree 或 B+Tree 等多叉树实现, 具有较好的随机读, 但是随机写性能比较差(数据在逻辑上相离很近但物理却可能相隔很远), 写耗时远大于读耗时;
LSM-Tree 优化了随机写, 最新写入的 KV 在内存中进行排序,为了防止宕机而丢失内存中的数据,LSM-Tree 还使用了 WAL 日志机制,新写入的数据同时还会写入磁盘的 WAL 日志中,用于宕机后的数据恢复。WAL 一般使用磁盘顺序写入,可以提供非常好的写操作性能,大约等于磁盘的理论速度,也就是200~300 MB/s
- 在内存中排好序的数据,会写入磁盘,与下层的文件合并为更大的文件;
- 所以说 LSM-Tree 写效率提高,也是有代价的:多了文件的合并操作(compaction),同时上下层的磁盘文件有冗余数据;
LSM-Tree 特性解析
➤ LSM(The Log-Structured Merge-Tree) 即 日志结构合并树, 有两个特性: 日志结构 + 合并树. OSDI ‘06 Paper
- 日志:
- 数据被插入时, 首先写 WAL(Write Ahead Log), WAL 是磁盘顺序写, 写入速度很快
- 合并树:
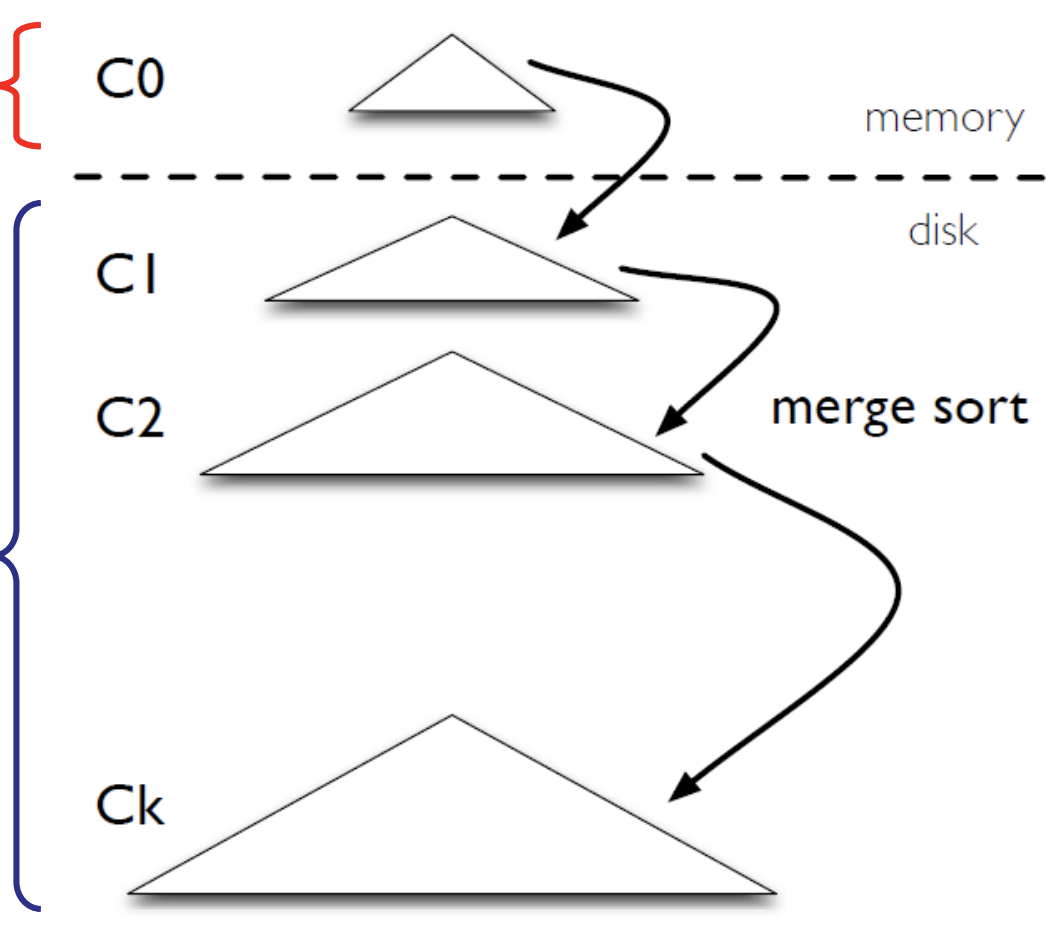
- LSM-Tree 的树结构分两部分, 存储于内存中的 C0层, 以及存储于磁盘的 C1..Ck 层;
- C0层一般使用 RB-Tree 或 SkipList 实现, WAL 里的数据首先被写入 C0树, C0树按照 Key 有序存储;
- 当 C0层的大小超过阈值, 会与下一层的 C1层进行合并(Compaction), 成为新的 C1层, 同时清空 C0层, 合并过程类似归并排序中的“归并”过程;
- 同样 C1层超过大小阈值也会与 C2层的文件进行合并… 所以从 C0-Ck 每层的文件容量逐层增大;
- C1..Ck 层一般用有序文件(sstable)实现;
写入过程: C0层总是最新写入的数据, Ck 层则包含最旧的数据, 当更新一个 K 对应的 val 时,只会写入最上层, 下层的旧数据并不会更新,而是当上下两层合并时, 上层的新数据会覆盖掉下次的旧数据 ;
查询过程: 从 C0层开始查询, 如果找不到就在下一层查找, 所以相比较 B+Tree, LSM-Tree 的读性能会差一些;
删除过程: 仅在 C0层插入一个带有删除标记的 Entry,并不真正删除下层文件中的数据,而是等待合并时 …
Scan过程: @todo
LevelDB 如何实现 LSM-Tree
LevelDB is a key-value store based on LSM-trees:
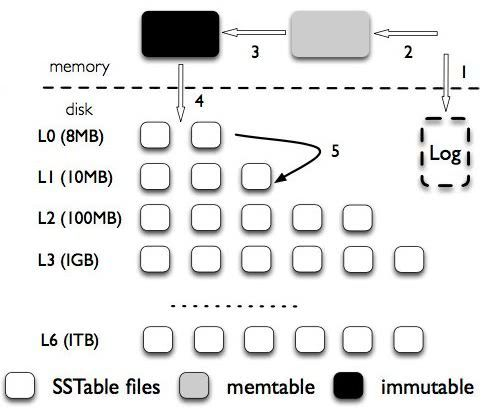
LevelDB 是如何实现 LSM-Tree 的:
- LevelDB 的 WAL(图中1)
内存中的 MemTable 层:
- WAL 的数据首先被写入 memtable, 当 memtable 的数据超过阈值, memtable 变为 immutable memtable(不可写入的), 新创建一个 memtable 用于写入新数据, immutable memtable 中的数据 flush 写入磁盘的 L0层;
- 把内存里面不可变的 immutable memtable flush 到硬盘上的 SSTable 层中,此步骤也称为 Minor Compaction,这里需要注意在 L0层的 SSTable 是没有进行合并的,所以这里的 key range 在多个 SSTable 中可能会出现重叠,在层数大于 0 层之后的 SSTable,不存在重叠 key。
磁盘中的 SSTable 层:
- 图中的 L0..L6, 每层都由数个 SStable (Sorted String Table)组成, 每层的总大小是上一层的10倍(图中4~5), SSTable 的概念来自 google 《BigTable》的论文, [[../_attachments/Persistent Key-Value Stores.pdf|Persistent Key-Value Stores]], 按 Key 顺序存储的键值对集合
- 此步骤也称为Major Compaction,这个阶段会真正的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于 SSTable 都是有序的,我们可以直接采用 merge sort 进行高效合并。
Write & Compaction:
![[../_images/LevelDB-LSM-Tree2.png]]
Search:
![[../_images/LevelDB-LSM-Tree3.png]]
图参考自:http://www.cse.cuhk.edu.hk/~mcyang/csci5550/2020S/Lec09%20Persistent%20Key-Value%20Stores.pdf
Delete:
目前的 LSM-Tree 写入的时候,会写一条记录,删除的时候,标志一个 tombstone (类似 leveldb 的 type)
对比 B-Tree
LSM-Tree 对比 B-Tree,某种程度也相当于对比 HBase 和 MySQL 两种不同的数据库。
LSM-tree 正是能够借助内存缓冲将大量的随机写入转化成批量的顺序写入,使得最终磁盘承载的写入次数对数级减少,极大地提升了写入吞吐量。
此外,当更新一条数据时,B+Tree 采用原地更新方式(in-place update),整个叶子节点对应的数据页都要读取和写回,带来了额外的读写放大。因此,磁盘随机读写成为 B+Tree 的瓶颈,使其适用于读多写少的场景。
数据在 MySQL 和 HBase 中存储差异:
即使某列为空,MySQL 依然会为该字段保留空间,因为后续有可能会有 update 语句来更新该记录,填补这列的内容。
而 HBase 则是把每一列都看做是一条记录,row+列名作为 key,data 作为 value,依次存放。假如某一行的某一个列没有数据,则直接跳过该列。针对稀疏矩阵的大表,HBase 能大大节省存储空间。
Reference
@ref:
- LSM 算法的原理是什么? - 知乎
- LSM-Tree 的应用及原理 - 知乎
- [[../_attachments/Persistent Key-Value Stores.pdf|Persistent Key-Value Stores]]
- Ssystem|分布式|Bigtable - 知乎