按存储模型分类
按数据模型分类:关系型 & 非关系型,后者又包括 KV 型、面向文档型、图数据库…… 一般来说,用NoSQL 作为“非关系型数据库”的泛称。
关系型(relational):关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)。一般使用 B-Tree 作为索引;
典型产品:MySQL、PostgreSQL、SQLite、SqlServer
非关系型(non-relational):
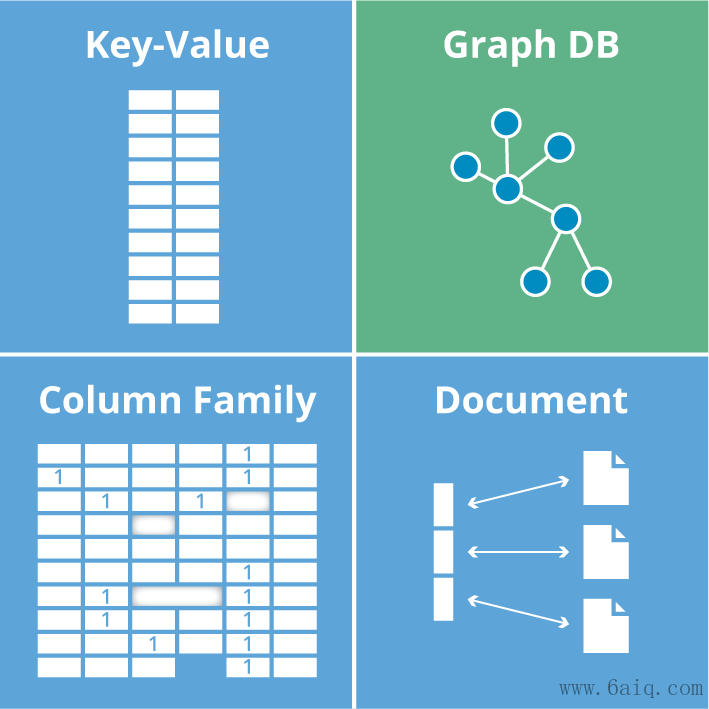
KV 存储:键值数据库将数据存储为键值对集合,其中键作为数据的唯一标识。可以使用哈希表、跳表等构建索引;
典型产品:Redis、HBase列存储数据库:列式存储(column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。我们知道,平时的查询大部分都是条件查询,通常是返回某些字段(列)的数据。对于行存储数据,数据读取时通常将一行数据完全读出,存在数据冗余,而列存储,每次读取的数据只是需要的部分,不存在冗余性问题。
典型产品:HBase面向文档数据库(document-based):此类数据库存储的是文档(XML、JSON、BSON 等格式),这些文档具备可述性(self-describing),呈现分层的树状结构(hierarchical tree data structure)。一般使用倒排索引;
典型产品:MongDB、ElasticSearch图数据库(graph db):存储图形关系的数据库。一般的图数据库至少包含图存储、图查询、图分析这三种功能,典型产品:Neo4J、InfoGrid等
OLTP vs OLAP
OLTP(online transcation processing)联机事务处理:
- 多用来解决业务中的事务(ACID: 原子性,一致性,…)问题, 随机读写, 频繁的更改/删除;
- 不适合数据分析场景: 场景特点(数据量大), 分析和计算能力(OLTP没有, 只能查询到业务层再处理) // 关系型数据库, count/max/group by的实现?
OLAP(online analytical processing)联机分析处理:
- OLAP不关数据的事务特性, 也不关注数据的频繁删改, 而是关注大量数据的多维度/复杂分析和计算
- OLAP的分类:
- 多维度OLAP(Multi-Dimensional OLAP,简称MOLAP):
对数据需要分析的维度预先建模, 在数据存储的物理层面使用cube的结构进行存储(?) 缺点是数据需要预先建模, 优点比下面的关系型OLAP分析计算更快 - 关系型OLAP(Relational OLAP,简称ROLAP):
使用类似关系型数据库的存储模型(例如用label取代column), 使用类似SQL的语句进行分析查询, 分析计算更自由(相比多维度OLAP预先建模的方式), 但是海量数据下计分析算速度不如多维度OLAP
- 多维度OLAP(Multi-Dimensional OLAP,简称MOLAP):
TSDB(时序数据库)
➤ 时序业务的特点:
- 持续产生海量数据的业务: 持续(每秒都产生,没有突增热点)和海量(每秒千万/亿条)
- 比如监控系统产生的日志
- 比如可穿戴设备+物联网设备产生的日志
- 几乎全都是写入, update/delete操作极少
- 近期数据价值更高, 久远的数据极少被访问, 所以数据以流式处理居多
- 没有关系型数据库的列, 一条数据不同维度的数据用标签区别, 可以以标签聚合查询(例如查询监控系统中,统计某API几天内访问量)
➤ TSDB 核心技术:
- 高吞吐写入能力:
- 系统具备水平扩展的能力;
- 单机具备高吞吐量,一般使用 LSM 架构实现;
- 数据分级存储/数据TTL: x小时内的使用内存, x天内使用SSD, 更久远的使用HDD, 或者根据TTL删除
- 多标签查询: 多使用位图索引 or 倒排索引
- 聚合查询: 预聚合
➤ 常见 TSDB 产品:
Influxdb:Influxdb是业界比较流行的一个时间序列数据库,特别是在IOT和监控领域十分常见。其使用go语言开发,突出特点是性能。特性:
- 自定义 TSM 引擎
- 简单,高性能的 HTTP 查询和写入 API
- SQL-like查询语言,简化查询和聚合操作
Opentsdb:一个基于 Hbase 的时间序列数据库(新版也支持 Cassandra)@link
- 在数据压缩上,时间戳采用 delta 编码进行压缩,数据值采用 XOR 进行压缩;
- 存储与计算解耦,为 IoT 场景海量数据、动态热点的数据特征量身打造,方便按照并发度和存储量按需独立扩容。采用分布式架构,支持横向水平扩展;
- 空间聚合,支持按照不同的 tag 进行空间聚合和分组计算。
Prometheus 是一个开源的服务监控系统和时间序列数据库。独立地开源监控系统和告警工具,广泛应用于 Kubernetes 生态
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch 的时序优化可以参考文章: 《elasticsearch-as-a-time-series-data-store》
@ref: http://hbasefly.com/2017/11/19/timeseries-database-1/?rulkna=n0cfu1