![]()
Kafka架构
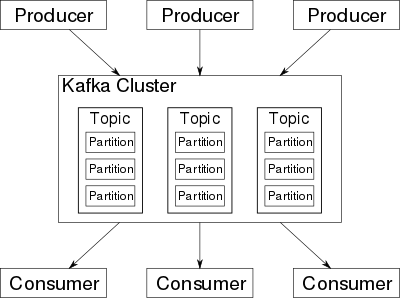
Kafka存储的消息来自任意多被称为“生产者”(Producer)的进程。数据从而可以被分配到不同的“分区”(Partition)、不同的“Topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
Kafka高效地处理实时流式数据,可以实现与Storm、HBase和Spark的集成。作为群集部署到多台服务器上,Kafka处理它所有的发布和订阅消息系统使用了四个API,即生产者API、消费者API、Stream API和Connector API。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如JMS、AMQP等。
Kafka架构的主要术语包括Topic、Record 和 Broker。Topic 由Record组成,Record持有不同的信息,而Broker则负责复制消息。Kafka有四个主要API:
- 生产者API:支持应用程序发布Record流。
- 消费者API:支持应用程序订阅Topic和处理Record流。
- Stream API:将输入流转换为输出流,并产生结果。
- Connector API:执行可重用的生产者和消费者API,可将Topic链接到现有应用程序。