集群概述
对客户端来说,整个 cluster 被看做是一个整体,客户端可以连接任意一个节点(node)进行操作,就像操作单一 Redis 实例一样,当客户端操作的 key 没有分配到该 node 上时,Redis 会返回转向指令,指向正确的 node,这有点像浏览器页面的302 redirect 跳转。客户端不需要连接集群所有节点,只要连接集群中任意一个节点即可。
- Redis Cluster 中,每个 Redis 实例被称为节点(node),整个集群被 Sharding 为 16384个 slot(槽);
- 对于每个写入的键值对,根据 key 进行散列,分配到这16384个 slot 中的某一个中。通过
CRC16(key)%16384计算 Key 属于哪个槽;如果 key 中包含{},那么集群在计算哈希槽的时候只会使用{}中的内容,而不是整个键,{}内的内容称为 hash_tag,这个机制可以让客户端可以控制哪些 key 落入同一个槽; - Redis 集群中的每个 node(节点)负责分摊这16384个 slot 中的一部分。当动态添加或减少 node 节点时,需要将16384个槽做个再分配,槽中的键值也要迁移;
- 为了增加集群的可访问性,官方推荐的方案是将 node 配置成主从结构,即每个 master 都配置 n 个 slave ;
- 如果主节点失效,Redis Cluster 会根据选举算法从 slave 中选择一个上升为主节点。这非常类似前篇文章提到的 Redis Sharding 场景下服务器节点通过 Sentinel 监控架构成主从结构,只是 Redis Cluster 本身提供了故障转移容错的能力。
集群安装
- 使用redis-trib.rb创建集群
redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 - 添加主节点:
redis-trib.rb add-node 127.0.0.1:7007 127.0.0.1:7001 - 当添加了一个主节点后,需要重新分配哈希槽:
redis-trib.rb reshard 127.0.0.1:7001 - 添加从节点, 添加一个port为7008的Redis实例做为7007的从节点:
redis-trib.rb add-node --slave --master-id cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 127.0.0.1:7008 127.0.0.1:7001- 注: 主节点id可以在client中使用
cluster nodes命令查询。
- 注: 主节点id可以在client中使用
- 删除节点:
redis-trib.rb del-node 要删除的节点的ip和端口 节点id
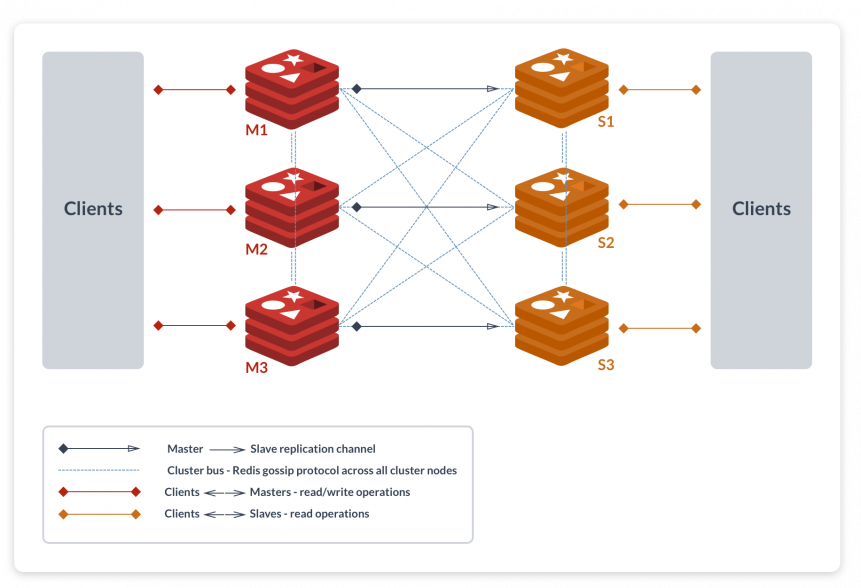
Redis Cluster 架构概述
节点间通讯:
- 所有的 redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度和带宽,详见「Gossip 协议解析」
节点和槽:
- 将所有数据分为16384个槽(Slot), 每个 redis 节点分得一部分槽, 每个 redis 节点都存储了槽和节点的对应关系, 客户端也会缓存槽和节点的对应关系
- 槽的编号从
0~0x3FFF, 所以槽的总数 = 16384 = 0x3FFF+1
查询过程:
- 客户端与 redis 节点直连,不需要中间 proxy 层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- 客户端(以JedisCluster为例)读写时, 首先计算出Key在哪个槽: Slot =
crc(Key) & 0x3FFF, 然后根据”槽-节点”的表直接访问Redis节点 // 在JedisClusterInfoCache类中,slots这个Map本地缓存保存的也是slot槽和主节点的连接池; - 如果Redis节点包含查询的Key, 直接返回数据, 如果不包含, 则返回’MOVED’重定向错误
- 客户端收到 MOVED 响应, 使用 cluster slots 命令更新 slots 缓存(renewSlotCache 方法)
- 客户端重复上述查询过程
如果 slot 正在向别的节点迁移中,返回的是 ASK(类似临时重定向)
一些查询命令的优化:
- 如果是
keys这种涉及所有节点的命令, 通过 Spring 的AsyncTaskExecutor发送命令给所有节点, 然后处理异步返回的结果 - 如果是
mget这种可能涉及部分节点的命令, 先把所有的 key 按节点分组, 然后异步执行
故障转移/投票机制:
- Redis 集群中每一个节点都会参与投票,如果当半数以上的节点认为一个节点通信超时,则该节点 fail。
- 当集群中任意节点的 master(主机)挂掉, 且这个节点没有 slave(从机),则整个集群进入 fail 状态。
Gossip协议解析
Gossip 是一个p2p模式的协议, 节点之间不断交换彼此的元数据信息, 元数据信息包括自己和已知其他节点的状态, 交换一段时间后最终每个节点都可以同步到最新的状态数据, Gossip主要有以下4类消息:
- MEET: 类似”握手”, 消息中包括作为发送者的 Redis节点的信息 以及其他已知 Redis节点信息(节点id,负责槽位,节点标识等等)
- PING: 消息中包含内容同MEET消息, PING作为节点之间信息交换 & 心跳检查
- PONG: 接收到MEET/PING后, 需要返回一个PONG, 告知对方自己状态正常
- FAIL: 节点发现另外某节点不可用时(没收到PONG), 会向自己已知的所有节点发送FAIL广播
考虑到频繁地交换信息会加重带宽(集群节点越多越明显)和计算的负担,
Redis Cluster内部的定时任务每秒执行10次,每次遍历本地节点列表,对最近一次接受到pong消息时间大于cluster_node_timeout / 2的节点立马发送ping消息,
此外每秒随机找5个节点,选里面最久没有通信的节点发送ping消息。
同时 ping 消息的消息投携带自身节点信息,消息体只会携带1/10的其他节点信息,避免消息过大导致通信成本过高。
故障发现、故障转移
- 如果某个主节点宕机, 集群内的其他机器通过 PING-PONG 很快发现宕机, 并通过广播 FAIL 消息,当超过半数的主节点认为宕机,则确认是”客观下线”;
- 宕机主节点对应的从节点,收到主节点宕机的消息, 发起选举广播,请求其他具有投票权的主节点给自己投票;
- 选举过程和 Redis Sentinel 方式类似,超过半数的选票则认为自己当选, 需要注意的是从当选为主节点之后的操作:
- 自己变为主节点, 停止从原主节点复制工作
- 让原主的其他从节点变为自己的从
- 更新槽-节点的配置, 并广播给其他节点
槽位迁移、数据伸缩
无论是集群扩容还是收缩,本质上都是槽及其对应数据在不同节点上的迁移。一般情况下,槽迁移完成后,每个节点负责的槽数量基本上差不多,保证数据分布满足理论上的均匀。
常用的有关槽的命令如下:
CLUSTER ADDSLOTS slot1 [slot2]...[slotN]—— 为当前节点分配要负责的槽,一般用于集群创建过程。CLUSTER DELSLOTS slot1 [slot2]...[slotN]—— 将特定槽从当前节点的责任区移除,和ADDSLOTS命令一样,执行成功后会通过节点间通信将最新的槽位信息向集群内其他节点传播。CLUSTER SETSLOT slotNum NODE nodeId—— 给指定ID的节点指派槽,一般迁移完成后在各主节点上执行,告知各主节点迁移完成。CLUSTER SETSLOT slotNum IMPORTING sourceNodeId—— 在槽迁移的目标节点上执行该命令,意思是这个槽将由原节点迁移至当前节点,迁移过程中,当前节点(即目标节点)只会接收asking命令连接后的被设为IMPORTING状态的slot的命令。CLUSTER SETSLOT slotNum MIGRATING targetNodeId—— 在槽迁移的原节点上执行该命令,意思是这个槽将由当前节点迁移至目标节点,迁移过程中,当前节点(即原节点)依旧会接受设为MIGRATING的slot相关的请求,若具体的key依旧存在于当前节点,则处理返回结果,若不在,则返回一个带有目标节点信息的ASK重定向错误。其他节点在接受到该槽的相关请求时,依旧会返回到原节点的MOVED重定向异常。
在完成 slot 在原节点和目标节点上状态设置(即上面最后两条命令)后,就要开始进行具体 key 的迁移。
CLUSTER GETKEYSINSLOT slot total—— 该命令返回指定槽指定个数的key集合MIGRATE targetNodeIp targetNodePort key dbId timeout [auth password]—— 该命令在原节点执行,会连接到目标节点,将key及其value序列化后发送过去,在收到目标节点返回的ok后,删除当前节点上存储的key。整个操作是原子性的。由于集群模式下使用各节点的0号db,所以迁移时dbId这个参数只能是0。MIGRATE targetNodeIp targetNodePort "" 0 timeout [auth password] keys key1 key2...—— 该命令是上面迁移命令基于pipeline的批量版本。
在整个slot的key迁移完成后,需要在各主节点分别执行CLUSTER SETSLOT slotNum NODE nodeId来通知整个slot迁移完成。redis-trib.rb 提供的reshard功能便是基于官方提供的上述命令实现的。
集群的扩展过程实际上就是启动一个新节点,加入集群(通过 gossip 协议进行节点握手、通信),最后从之前各节点上迁移部分 slot 到新节点上。
集群的收缩过程除了除了将待下线节点的槽均匀迁移到其他主节点之外,还有对节点的下线操作。官方提供了
CLUSTER FORGET downNodeId命令,用于在其他节点上执行以忘记下线节点,不与其交换信息,需要注意的是该命令有效期为60s,超过时间后会恢复通信。一般建议使用 redis-trib.rb 提供的 del-node 功能。
客户端 jedis-cluster
Jedis 是 redis 的 java 客户端,JedisCluster 则是 Jedis 根据 Redis 集群的特性提供的集群客户端。
上文介绍过了 redis 集群下操作 key 的详细流程,一般通过 redis-cli 启动客户端连接具体的节点时,要操作的 key 若不在这个节点上时,服务端会返回 MOVED 重定向错误,这时需要手动连接至重定向节点才能继续操作。或者 redis-cli 连接服务节点时加上-c 参数,就可以使用 redis-cli 提供的自动重定向机制,在操作其他服务节点的 key 时会进行自动重定向,避免客户端手动重定向。
JedisCluster 作为操作 Redis 集群的 java 客户端,同样遵守 RedisCluster 提供的客户端连接规范,本节从源码的角度去看其具体是怎么做的。
@ref: