键值对数据库
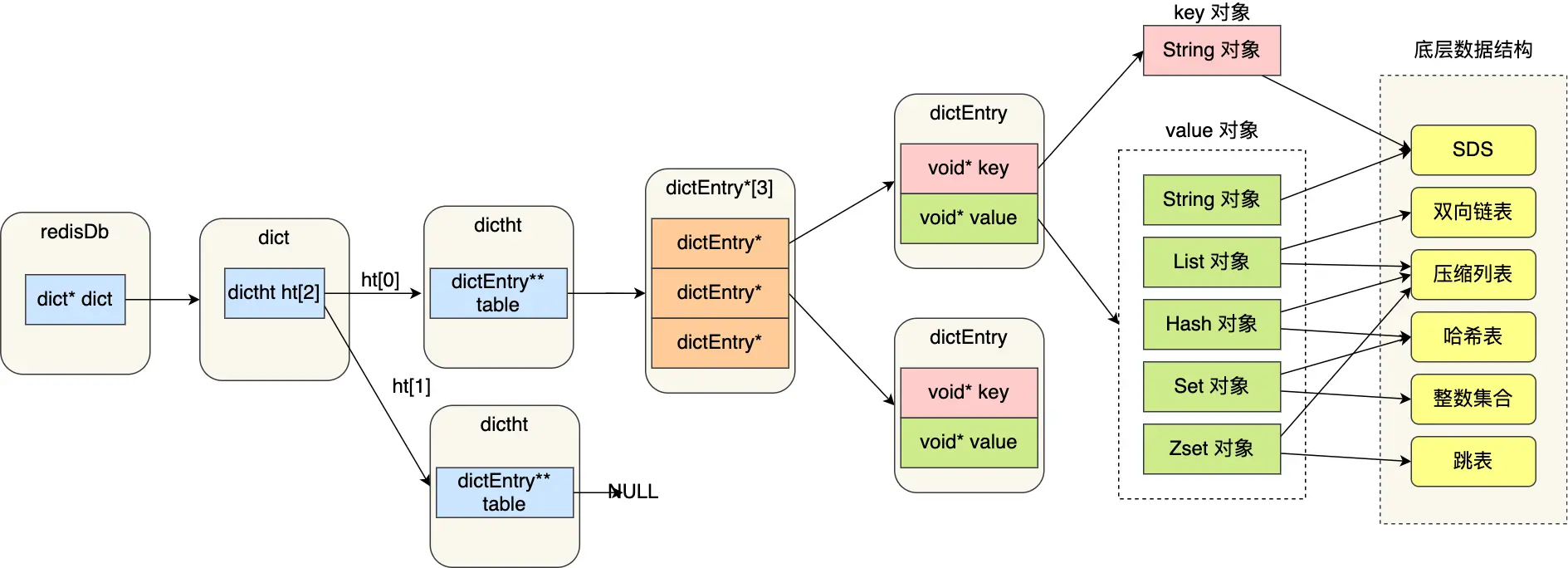
- 每个 redisServer 实例包含多个 DB,每个 DB 在内存中使用 redisDb 结构体表示;
- 每个 redisDb 包含2个 dictht(dict hashtable)字典,字典中包含了所有的键值对,我们也称该字典为键空间(key space)。其中第二个字典 ht[1] 指向 null,只在rehash 过程中才会被分配内存;
- 每个键值对 对应的数据结构是
dictEntry,其主要包含三个成员:key、value、next,其中 key 和 value 的类型都是void*,该指针指向类型是redisObject; redisObject是 Redis 中各种数据类型的抽象,主要包含三个成员:type、encoding、ptr,根据不同的 type 和 encoding,ptr 可以指向 String,List,Hash,Set,SortedSet 等…
typedef struct redisObject { |
redisObject
redisObject 主要成员:
unsigned type:存储对象的类型,也即 ptr 指针指向的数据类型(String、List、Hash、Set、ZSet 中的一种)unsigned encoding:存储对象使用的编码方式,也即 ptr 指针指向的数据块用何种编码,不同的编码方式使用不同的数据结构进行存储。例如 String 类型的对象,可能的编码方式有 REDIS_ENCODING_INT、REDIS_ENCODING_EMBSTR、REDIS_ENCODING_RAW 三种;unsigned lru:存储 redisObject 上次被访问的时间戳,详见「Key过期」void *ptr:根据 type+encodng,可能指向不同的数据结构
type 和 encoding 的组合:
| 数据类型(type) | 编码格式(encoding) |
|---|---|
| REDIS_STRING | REDIS_ENCODING_INT |
| REDIS_ENCODING_EMBSTR | |
| REDIS_ENCODING_RAW | |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST |
| REDIS_ENCODING_ZIPLIST(压缩列表) | |
| REDIS_ENCODING_QUICKLIST(3.2新增) | |
| REDIS_SET | REDIS_ENCODING_INTSET |
| REDIS_ENCODING_HT(哈希表) | |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_SKIPLIST(跳表) | |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_HT |
Redis 数据类型的底层数据结构随着版本的更新也有所不同,比如:
- 在 Redis 3.0 版本中 List 对象的底层数据结构由「双向链表」或「压缩表列表」实现,但是在 3.2 版本之后,List 数据类型底层数据结构是由 quicklist 实现的;
- 在最新的 Redis 代码(还未发布正式版本)中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
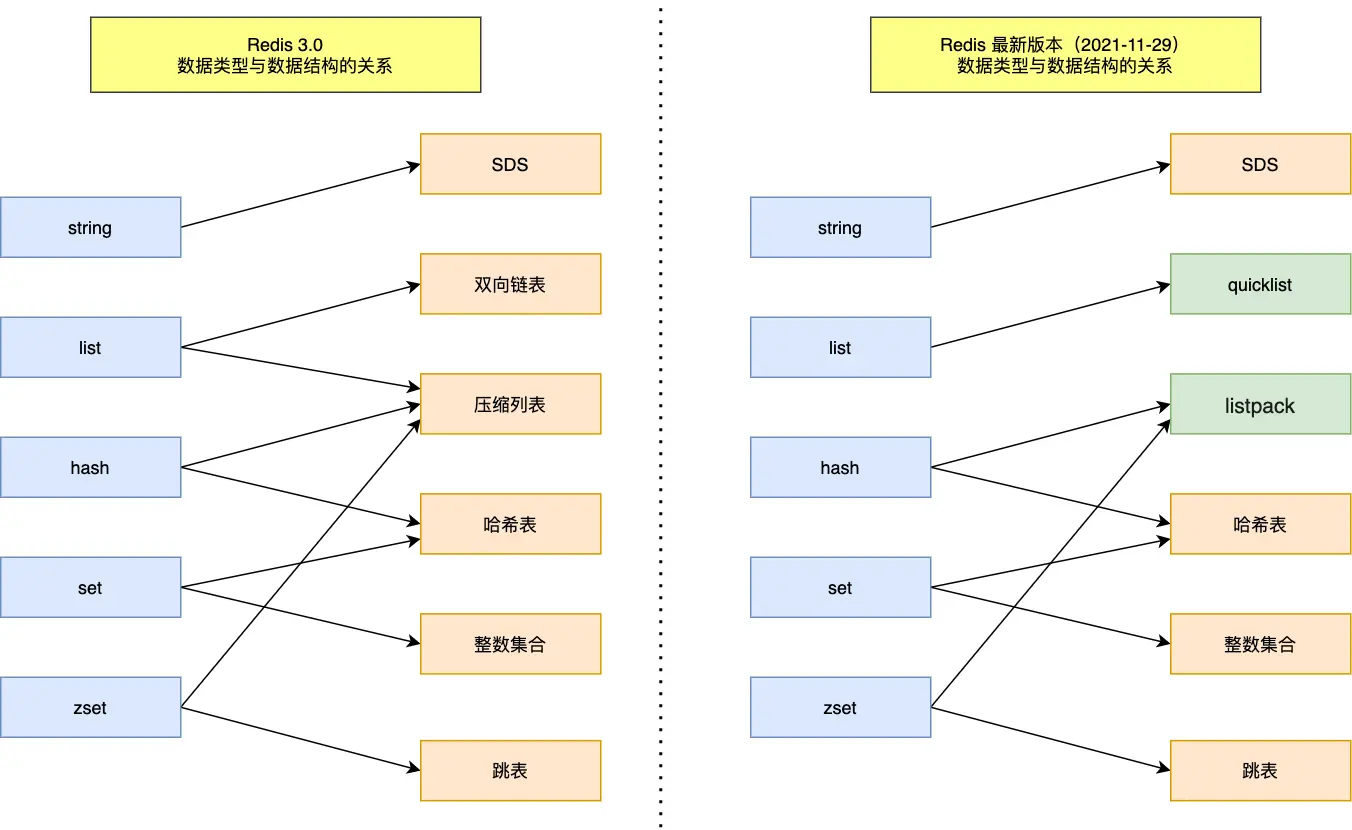
数据结构的实现
String
Redis 的字符串被称为 SDS(Simple Dynamic String,简单动态字符串)
➤ redisObject.type = REDIS_STRING, 支持 INT、EMBSTR、RAW 三种编码,
如果字符串的值是整数,同时可以使用 long 来进行表示,那么 Redis 将会使用 INT 编码方式,INT 编码方式会将 RedisObject 中的
*ptr指针直接改写成 long ptr,ptr 属性直接存储字面量:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-1.png]]如果字符串的值是字符,同时字符串的大小 < 32个字节,那么 Redis 将会使用 EMBSTR 编码方式,RedisObject 和 SDS 共同使用同一块内存单元,Redis 内存分配器只需要分配一次内存:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-2.png]]如果字符串的值是字符,同时字符串的大小>32个字节,那么 Redis 将会使用 RAW 编码方式。RedisObject 和 SDS 是分开申请的两块内存:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-3.png]]
➤ 编码转换 & 升级:
如果字符串的值不再是整数或者用 long 无法进行表示,那么 INT 编码方式将会转换成 RAW 编码方式。
如果字符串的值其大小大于32个字节,那么 EMBSTR 编码方式将会转换成 RAW 编码方式。
INT 编码方式不能转换成 EMBSTR 编码方式。
➤ 字符串类型的 redisObject,其 ptr 指向的是 SDS 类型(simple dynamic string)的实现(Redis 5.0):
struct __attribute__ ((__packed__)) sdshdr5 { |
- len,记录了字符串长度。这样获取字符串长度的时候时间复杂度只需要 O(1);
- alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过
alloc - len计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作; - flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,区别是 len 和 alloc 成员变量的类型不同;
- buf,字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据;
➤ SDS 设计解析:
- 字符串结尾判断使用 len,而不是
'\0',这样可以让 sds 也可以存储二进制数据; - sds 的 buf 数组有冗余的空间,减少了内存分配频率;
- 之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少;
- 指定了对齐方式
__attribute__ ((packed)),它的作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐 // 默认情况下编译器按照“字段相对于结构体首地址的偏移,能够被该字段的 size 整除”,
List
redisObject.type = REDIS_LIST,支持 ZIPLIST、LINKEDLIST 两种编码方式:
- 如果列表对象保存的元素的数量少于512个,同时每个元素的大小都小于64个字节,那么 Redis 将会使用 ZIPLIST 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-4.png]]
- 如果列表对象保存的元素的数量多于512个,或者元素的大小大于64个字节,那么 Redis 将会使用 LINKEDLIST 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-5.png]]
➤ 编码转换和升级:
如果列表对象保存的元素的数量多于512个,或者元素的大小大于64个字节,那么 Redis 将会使用 LINKEDLIST 编码方式。
➤ zlist (ZIPLIST 编码)的实现:连续的内存块
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-12.png]]
uint32_t
zlbytes:保存了 ziplist 占用的字节数,包含 zlbytes 字段本身占用的4个字节。uint32_t
zltail:最后一个entry的字节偏移量(非zlend)。用于从list的另一端执行pop操作(即倒序遍历)uint16_t
zllen:entry 的数目。当保存的 entry 大于2^16-2个 entry 时,则将该值设置为2^16-1,此时需要遍历整个 entry list 来计算 list 中的 entry 数目uint8_t
zlend:表示ziplist中的最后一个entry。字节编码等同于255(即FF)。表示ziplist的结束符
zlist 节点包含三部分内容:
- prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
- encoding,记录了当前节点实际数据的 类型和长度,类型主要有两种:字符串和整数。
- data,记录了当前节点的实际数据,类型和长度都由
encoding决定;
相比较链表型,zlist 节点没有 next 指针,并且根据 encoding 灵活决定 data 的大小,但是缺点也很明显:
- 连锁更新:一个 entry 被更新,假如长度发生变化,后续 entry 也都受影响,需要对 zlist 进行重新内存分配;
- zlist 除了用在 LIST,还可能用在 HashMap、Set 中,查找效率较差
➤ list (LINKEDLIST 编码)的实现:
typedef struct list { |
➤ 设计解析:
- list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
- list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需 O(1);
Redis 3.0 的 List 对象在数据量比较少的情况下,会采用 Zlist「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
HashMap
redisObject.type = REDIS_HASH,支持 ZIPLIST 和 HASHTABLE 两种编码方式:
- 如果哈希对象保存的键值对的数量少于512个,同时每个键值对中的键和值的大小都小于64个字节,那么 Redis 将会使用 ZIPLIST 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-6.png]]
- 如果哈希对象保存的键值对的数量多于512个,或者键值对中的键或值的大小大于64个字节,那么 Redis 将会使用 HASHTABLE 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-7.png]]
➤ 编码转换:
如果哈希对象保存的键值对的数量多于512个,或者键或值中的键和值的字符串的大小大于64个字节,那么 Redis 将会使用 HASHTABLE 编码方式。
➤哈希表的桶数组中的元素类型是 dictEntry:typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- dictEntry 结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。
- dictEntry 结构里键值对中的值是一个「联合体 v」定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或 double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。
➤ 哈希冲突:
- HashMap 使用链表法解决 hash 冲突
➤ Rehash:
- 触发条件:
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。负载因子 =
ht[0].used / ht[0].size - 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。负载因子 =
- 渐进式 Rehash 过程:
- 给
ht[1]分配空间,一般比ht[0]大 2 倍; - 在字典中维持一个索引计数器变量
rehashidx,并将它的值设置为0,表示 rehash 工作正式开始 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
- 随着字典操作的不断执行, 最终在某个时间点上,
- 给
Set
redisObject type = REDIS_SET,支持INTSET和HASHTABLE两种编码方式。
如果集合对象保存的元素的数量少于512个,同时每个元素都是整数,那么 Redis 将会使用 INTSET 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-8.png]]如果集合对象保存的元素的数量多于512个,或者元素不是整数,那么 Redis 将会使用 HASHTABLE 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-9.png]]
➤ 编码转换:
如果集合对象保存的元素的数量多于512个,或者元素不是整数,那么Redis将会使用HASHTABLE编码方式。
Sorted Set
redisObject type = REDIS_ZSET,支持 ZIPLIST 和 SKIPLIST 两种编码方式:
如果有序集合对象保存的元素的数量少于128个,同时每个元素的大小都小于64个字节,那么 Redis 将会使用 ZIPLIST 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-10.png]]如果有序集合对象保存的元素的数量多于128个,或者元素的大小大于64个字节,那么 Redis 将会使用 SKIPLIST 编码方式:
![[../_images/Redis-01b数据结构-内部实现-2023-07-05-11.png]]
注意 ZSET 的实现中,除了 skiplist,还有一个哈希表,当向 ZSET 插入数据的时候,会向 skiplist 和哈希表依次插入,哈希表是为了让 ZSCORE 等命令可以实现常数级复杂度;
➤ 编码转换:
如果有序集合对象保存的元素的数量多于128个,或者元素的大小大于64个字节,那么Redis将会使用SKIPLIST编码方式。
➤ 跳表的实现:
typedef struct zset { |
- zset 包含一个 dict 和一个 skiplist;
- zskiplist 包含 header 和 tail,指向头尾节点,level 记录当前跳表的最大层数;
- node 的 backward 指针,指向前面一个节点,方便倒序遍历;
- level 的 span (跨度),是为了快速计算该节点的 rank,forward 指向下个节点,正向遍历时使用;
![[../_images/Redis-01b数据结构-内部实现-2023-07-06-1.png]]
查询过程:
- 从最高层的头结点开始;
- 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层的下一个节点;
- 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点;
- 如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找;
复杂度分析:
- 查找的平均复杂度:O(logN)
构建过程:
- 插入一个 (ele,score) 对,首先计算在哪一层插入, 层数的计算代码,层数越高的概率越小,该层也就越稀疏:
|
- 随机生成的值(介于1到32之间)也即层数K,同时也是 level 数组的大小
- 确定了层数 K,则需要更新 K-1层上的索引;
@ref:
- 跳表复杂度分析:Redis 为什么用跳表而不用平衡树? - 掘金
- HBase 的 MemStore 使用了 JDK 中的跳表
ConcurrentSkipListMap@ref: https://juejin.cn/post/7084811033549733902
BitMap
@todo