ProtoBuf C++使用
ProtoBuf(Protocol Buffers )是Google的开源的序列化 & 反序列化工具 https://developers.google.com/protocol-buffers/
使用步骤:
- 定义proto文件,文件的内容就是定义我们需要存储或者传输的数据结构,也就是定义我们自己的数据存储或者传输的协议。
- 安装protocol buffer编译器来编译自定义的.proto文件,用于生成.pb.h文件(proto文件中自定义类的头文件)和 .pb.cc(proto文件中自定义类的实现文件)。
- 使用protocol buffer的C++ API来读写消息
protocol buffer 生成的函数, 除了getter和setter之外, 还有:
标准消息函数(Standard Message Methods)
每一个消息(message)还包含了其他一系列函数,用来检查或管理整个消息,包括:
bool IsInitialized() const; //检查是否全部的required字段都被置(set)了值。 |
Debug的API, 包括:
string DebugString() const; //将消息内容以可读的方式输出 |
解析&序列化(Parsing and Serialization)函数, 包括:
bool SerializeToString(string* output) const; //将消息序列化并储存在指定的string中。注意里面的内容是二进制的,而不是文本;我们只是使用string作为一个很方便的容器。 |
使用示例:
//test.cpp |
@ref: Protocol Buffers C++入门教程 - 云+社区 - 腾讯云
varint
@ref: Protobuf 终极教程 @todo
浅谈服务治理、微服务与Service Mesh
浅谈服务治理、微服务与Service Mesh(一):Dubbo的前世今生 - DockOne.io
浅谈服务治理、微服务与Service Mesh(二): Spring Cloud从入门到精通到放弃 - DockOne.io
浅谈服务治理、微服务与Service Mesh(三): Service Mesh与Serverless - DockOne.io
RPC通用框架
通用RPC框架图: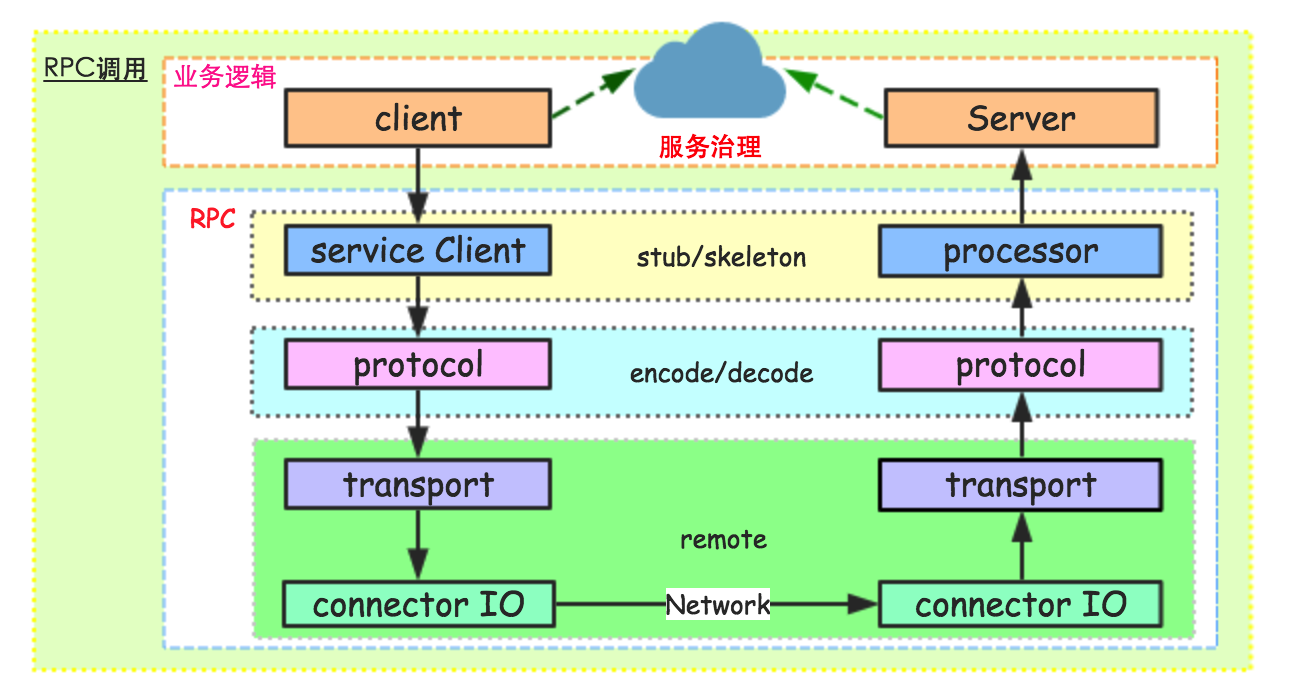
serviceClient:这个模块主要是封装服务端对外提供的API,让客户端像使用本地API接口一样调用远程服务。一般使用动态代理机制,当客户端调用api的方法时,serviceClient会走代理逻辑,去远程服务器请求真正的执行方法。类似RMI的stub模块。
processor:在服务端存在很多方法,当客户端请求过来,服务端需要定位到具体对象的具体方法,然后执行该方法,这个功能就由processor模块来完成。一般这个操作需要使用反射机制来获取用来执行真实处理逻辑的方法。类似RMI的skeleton模块。
protocol:协议层,一般协议层包括编码/解码,或者说序列化和反序列化工作;有的时候编解码不仅仅是对象序列化的工作,还有一些通信相关的字节流的额外解析部分。序列化工具有:hessian,Apache avro,G的 protobuf,FB的 Thrift,json系,xml系等等。在RMI中直接使用JDK自身的序列化组件。
Thrift和Protobuf的最大不同,在于Thrift提供了完整的RPC支持,包含了Server/Client,而Protobuf只包括了stub的生成器和格式定义。@ref Protobuf 和 Thrift对比-阿里云开发者社区
transport:传输层,主要是服务端和客户端网络通信相关的功能。这里和下面的IO层区分开,主要是因为传输层处理server/client的网络通信交互,而不涉及具体底层处理连接请求和响应相关的逻辑。
I/O:这个模块主要是为了提高性能可能采用不同的IO模型和线程模型,当然,一般我们可能和上面的transport层联系的比较紧密,统一称为remote模块。
Dubbo框架图参考: <RPC.01-浅谈服务治理、微服务与Service Mesh(zz)#Dubbo总体架构>
RPC技术要点
@ref 深入浅出RPC原理 | 没有期望的分布
- 序列化:
- JDK内置序列化
- Hessian: 在字节流里为每个field存储了类型信息, 可以不依赖serialVersionUID 进行版本匹配(Java类的UID被更改, 反序列化也没有问题)
- Kryo: “Kryo是一个快速高效的Java对象序列化框架,其在java的序列化上的性能指标甚至优于google著名的序列化框架protobuf,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用”
- Json:
- 编解码: 注意区分序列化的不同, RPC框架基本上都是基于Socket来实现通信层功能,但是在网络传输的数据由于网络链路和协议的问题,会出现半包、分包和粘包情况。这样就需要设计编解码协议头来解码网络流。比如dubbo给出的处理流程,可以清晰的看出序列化和编码之间的区别, 参考 Dubbo协议头
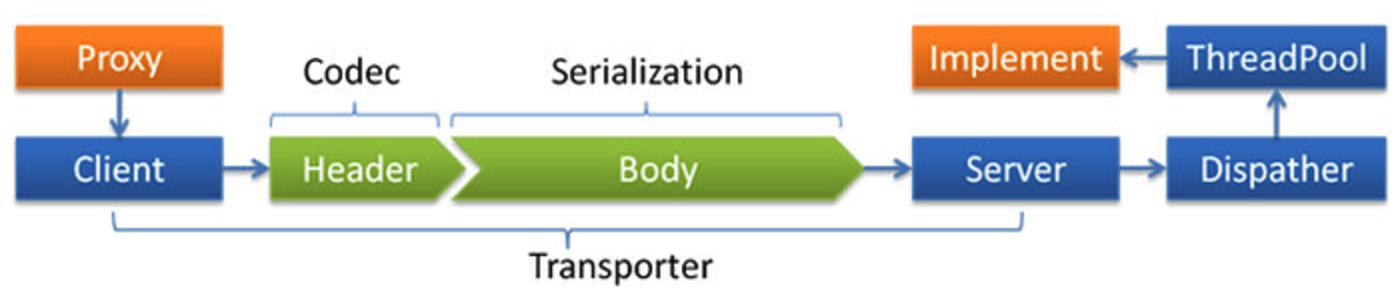
- 负载均衡:
- 一般通过client维护可用服务列表, client通过同server建立心跳 测试server是否存活, 如果server暂时不可用, client会把server暂时放入不可用列表, 一段时间后再次尝试建立心跳(类似熔断)
- 心跳服务可选的有 netty提供的 HashedWheelTimer, 在不要求高精度定时心跳的情况下提供了很高的性能
- Client侧负载均衡算法: ==> SystemDesign-负载均衡-算法
- 超时管理:
- client端的超时处理, 例如 future.get()
- server端的超时处理, 处理完后, 设定的超时参数比较, 如果发现已经超时则可以直接给client返回 err_code, 省去了序列化的时间
- 服务发现:
- 服务注册: server启动后注册服务信息 , 可选的存储服务有 zk/redis
- 服务感知/维护:
- 服务端和客户端与注册中心通过心跳上报运行情况
- 服务提供列表发生变化, 可以通过 client pull 或者 register push的方式
- IO模型: 参考 => Java Tutorials-09-NIO##Reactor三种常见线程模型
Dubbo协议头

- 协议头固定长度16个字节
- Magic: 共2字节
static final short MAGIC = (short) 0xdabb - Serialization id: 表示序列化类型ID,Dubbo支持多种序列化工具,比如hessian,jdk,fastjson等
- event表示事件,比如这个请求是heartbeat
- two way表示请求是否是需要交互返回数据的请求
- req/res表示该数据是请求还是响应
- status表示状态位,当响应数据的时候,根据该字段判断是否成功。
- id表示请求id
- data length则表示正文内容的长度