#status/chunking
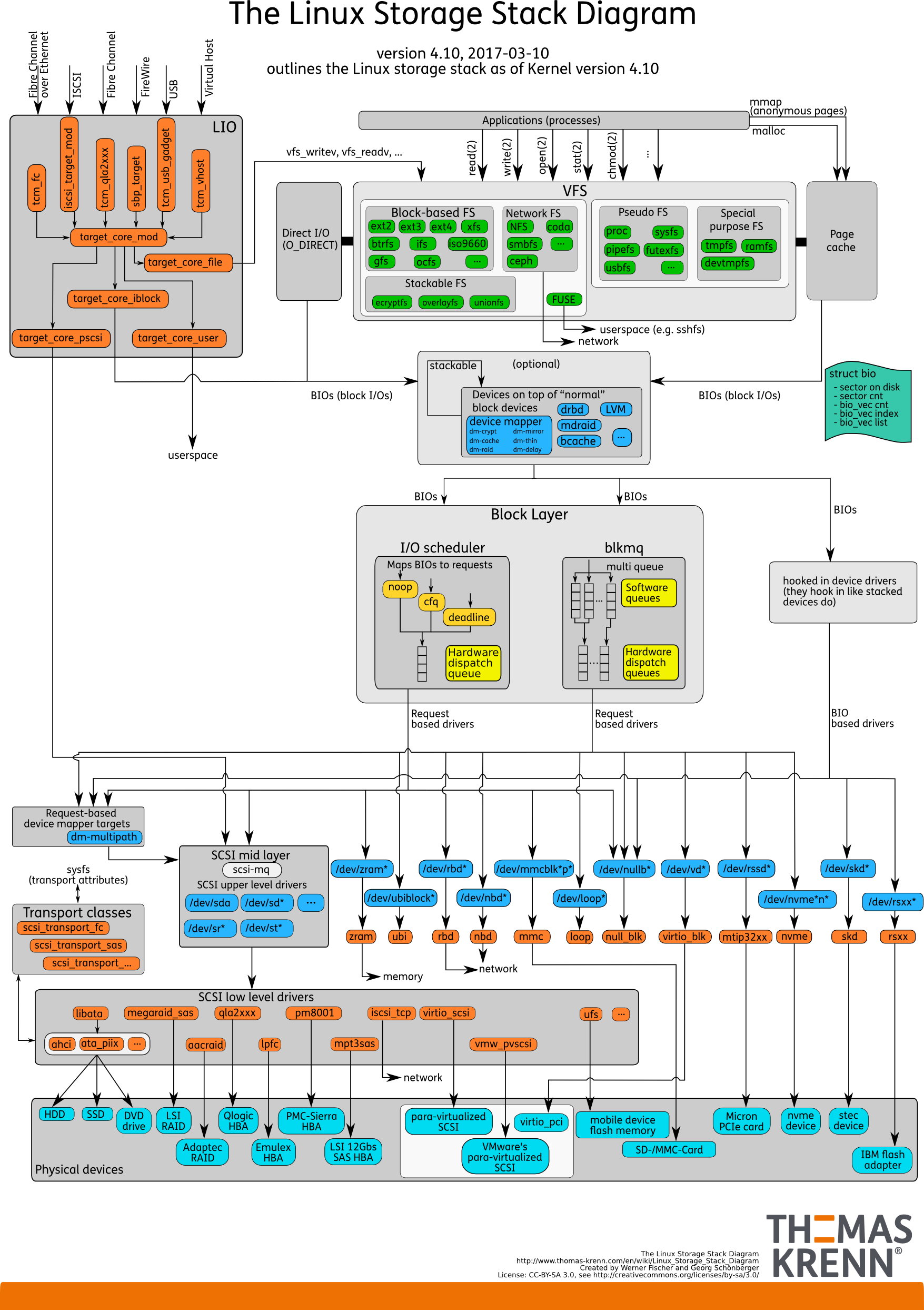
文件系统分层
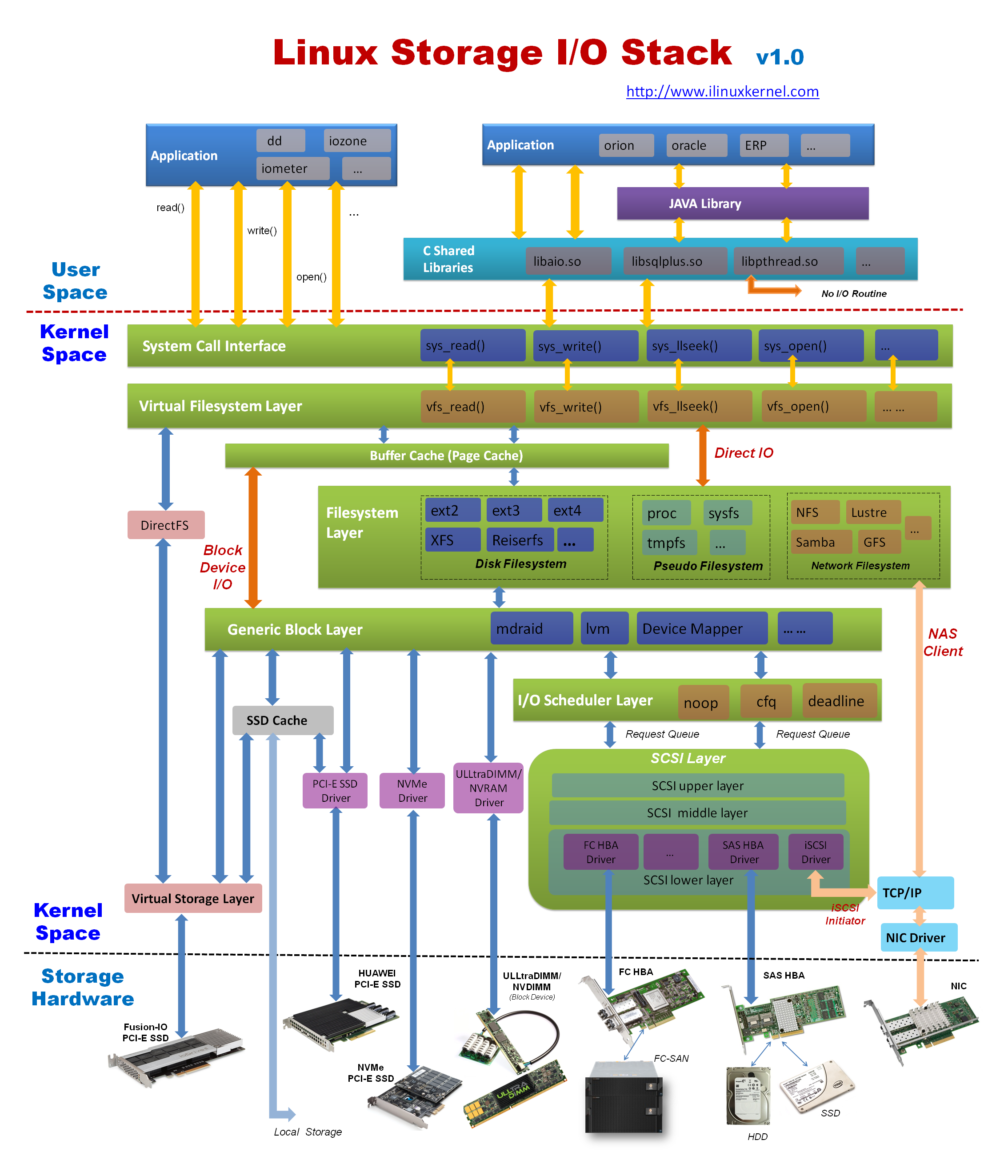
另一张图,侧重点是编程实体(库、函数)在 Linux 存储中的位置:
page cache(页缓冲)
@Inbox
缓存 I/O vs 直接 I/O
内核将文件的 IO 操作根据是否使用内核缓冲区(页高速缓存 page cache),将文件 IO 分为:Buffered IO 和 Direct IO 两种类型。进程在通过系统调用 open() 打开文件的时候,可以通过将参数 flags 赋值为 O_DIRECT 来指定文件操作为 Direct IO。默认情况下为 Buffered IO。
缓存 I/O:对数据的读写,实际上是对内核的缓冲区直接进行读写
- 缓存 I/O 的优点:1)在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;2)可以减少读盘的次数,从而提高性能。
- 缓存 I/O 的缺点:在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样,数据在传输过程中需要在应用程序地址空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
直接 I/O 就是应用程序直接访问磁盘数据,而不经过内核缓冲区
- 直接 IO 的优点:减少一次从内核缓冲区到用户程序缓存的数据复制。比如说数据库管理系统这类应用,它们更倾向于选择它们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。以及在文件随机读写时,也会用直接 IO
- 直接 IO 的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓存。通常直接 IO 与异步 IO 结合使用,会得到比较好的性能。(异步 IO:当访问数据的线程发出请求之后,线程会接着去处理其他事,而不是阻塞等待)
文件系统:inode 和 dentry
➤ Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node)和 目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
- 索引节点,即 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,inode 也同样都会被存储在硬盘中;
- 目录项,也就是 dentry,用来记录文件的名字、索引节点指针、以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。目录项这个数据结构不只是表示目录,也是可以表示文件。
由于索引节点唯一标识一个文件,而目录项记录着文件的名字,所以 目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个别名。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
➤ 磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
以上就是索引节点、目录项以及文件数据的关系,下面这个图就很好的展示了它们之间的关系:
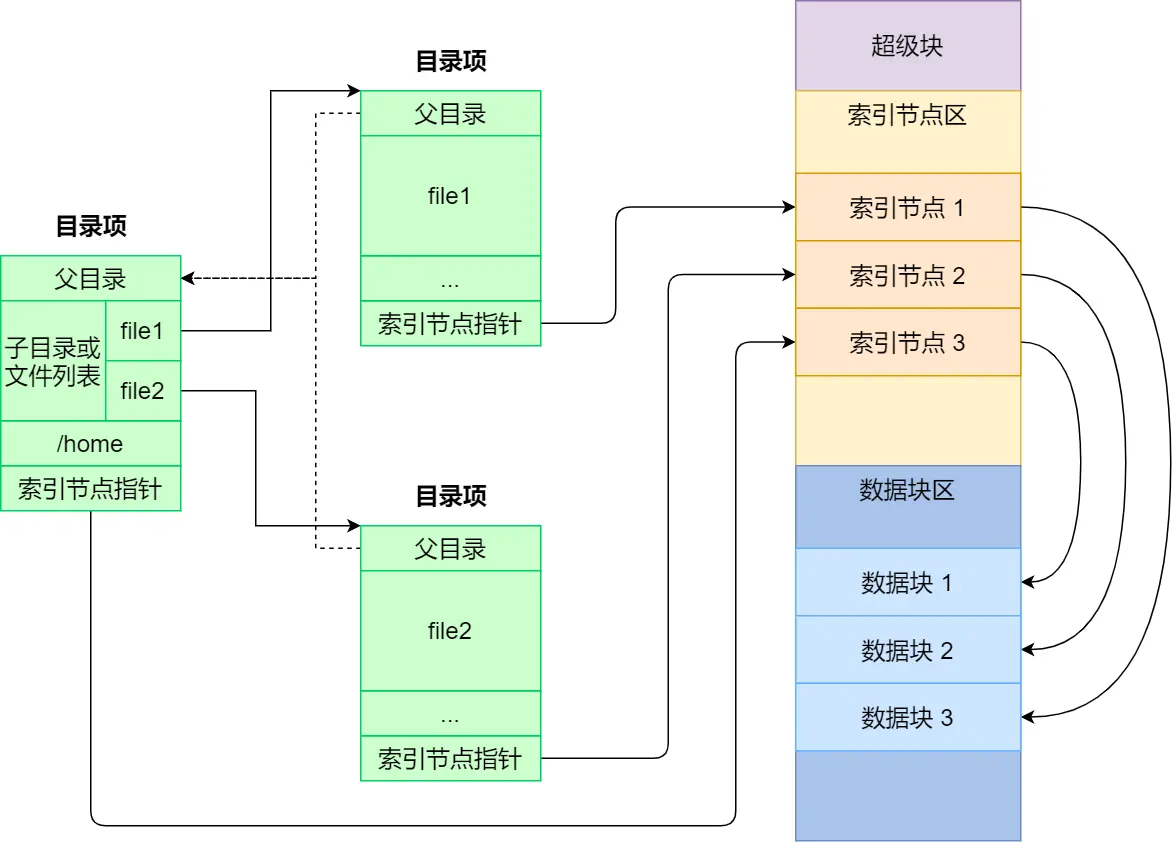
索引节点是存储在硬盘上的数据,那么为了加速文件的访问,通常会把索引节点加载到内存中。
另外,磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
- 索引节点区,用来存储索引节点;
- 数据块区,用来存储文件或目录数据;
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
- 超级块:当文件系统挂载时进入内存;
- 索引节点区:当文件被访问时进入内存;
文件系统:块组和块结构
上面提到 Linux 磁盘读写最小单位是 逻辑块(size = 4KB),但这个管理粒度太小了,EXT文件系统使用 块组 来管理更多的逻辑块
一般磁盘经过分区后,由 MBR + MBR GAP + 若干分区组成.
- MBR固定是512字节,446(引导写入区域)+64(分区表)+2(固定55aa)
- MBR+MBR GAP一般是2048bytes, 主要用于写入引导程序(如grub、LILO等),引导系统启动;
分区进行格式化后,在分区的开头会预留空间作为 Boot sector(一般1024bytes),剩下的空间切成若干个 块组,下图给出了 Linux Ext2 分区的 块组 示意图:
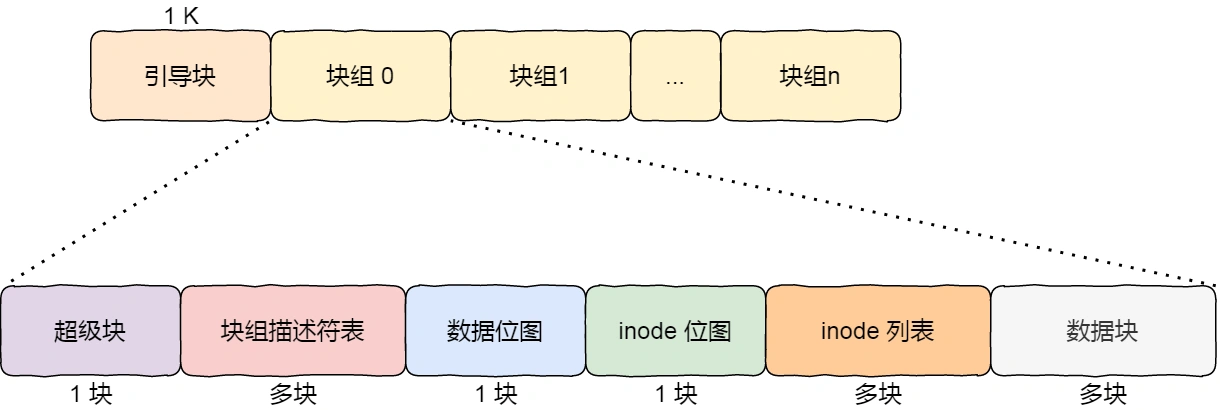
引导块,在系统启动时用于启用引导,每个分区都有一个,引导块后面接着就是一个一个连续的块组了,块组的内容如下:
超级块,包含的是文件系统的重要信息,比如 inode 总个数、块总个数、每个块组的 inode 个数、每个块组的块个数等等;
- 块组描述符,包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」;
数据位图 和 inode 位图,用于表示对应的 数据块 或 inode 是空闲的,还是被使用中。位图也占用1个逻辑块,因此以默认文件系统块大小计算,一个块组可以有32768(4096*8)个逻辑块;
inode 列表,列表的形式保存了文件的元数据信息,包括文件的inode id、大小、扩展属性和访问时间等内容。通常占用若干个逻辑块的大小;
数据块,上面元数据之外的存储区域都成为数据块区域,这些区域作为文件扩展属性和文件内数据的存放容器。
一个块组里是有重复的冗余数据的,比如 超级块 和 块组描述符表,这两个都是全局信息,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。
@ref:
IO 系统调用解析
open
open 负责在内核生成与文件相对应的 struct file 元数据结构,并且与文件系统中该文件的 struct inode 进行关联,装载对应文件系统的操作回调函数,然后返回一个 int fd 给用户进程。后续用户对该文件的相关操作,会涉及到其相关的 struct file、struct inode、inode->i_op、inode->i_fop 和 inode->i_mapping->a_ops 等。
注:文件操作对应的偏移存储于struct file中,每个open的文件单独维护一份,同一个文件的读写操作共享同一个偏移。
其整个内核逻辑流程可以用下图来表示: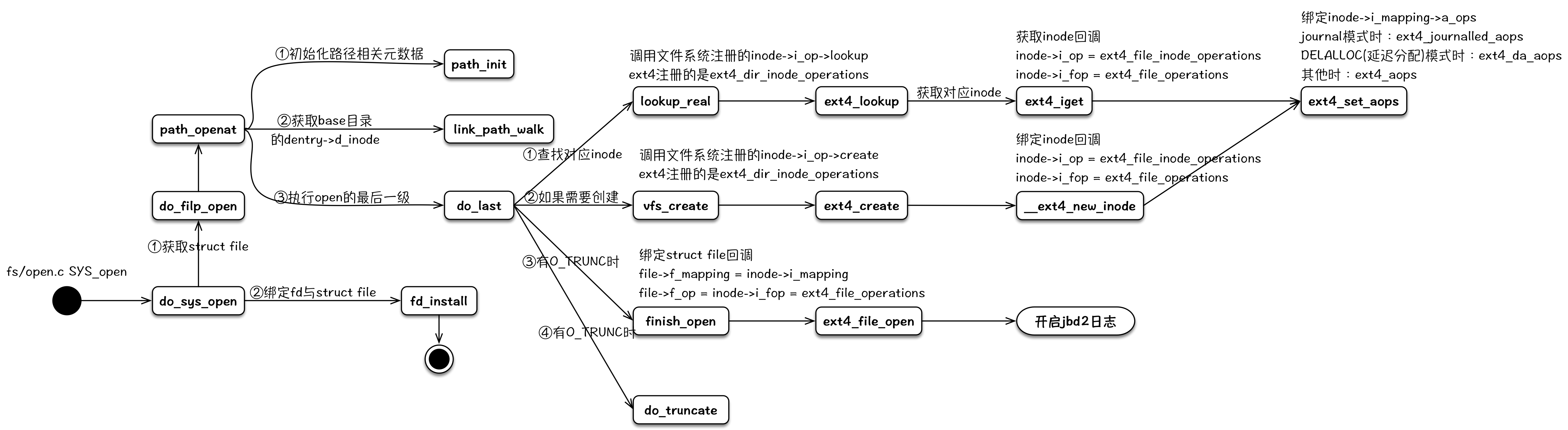
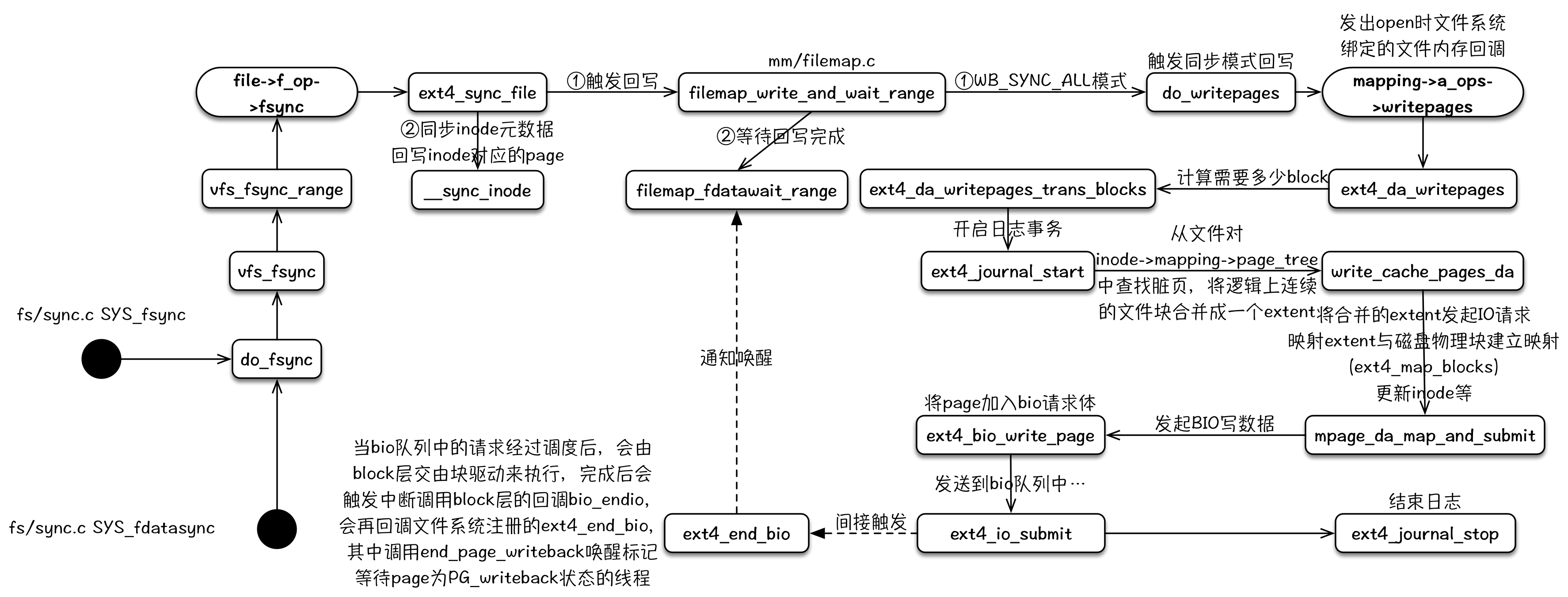
write
write 的写逻辑路径有好几条,最常使用的就是利用 pagecache 延迟写的这条路径,所以主要分析这个。在 write 调用的调用、返回之间,其负责分配新的 pagecache,将数据写入 pagecache,同时根据系统参数,判断 pagecache 中的脏数据占比来确定是否要触发回写逻辑。其详细的代码分析可以参考:《Linux 内核写文件过程》和 《Linux 内核延迟写机制》。
其整个内核逻辑流程可以用下图来表示:
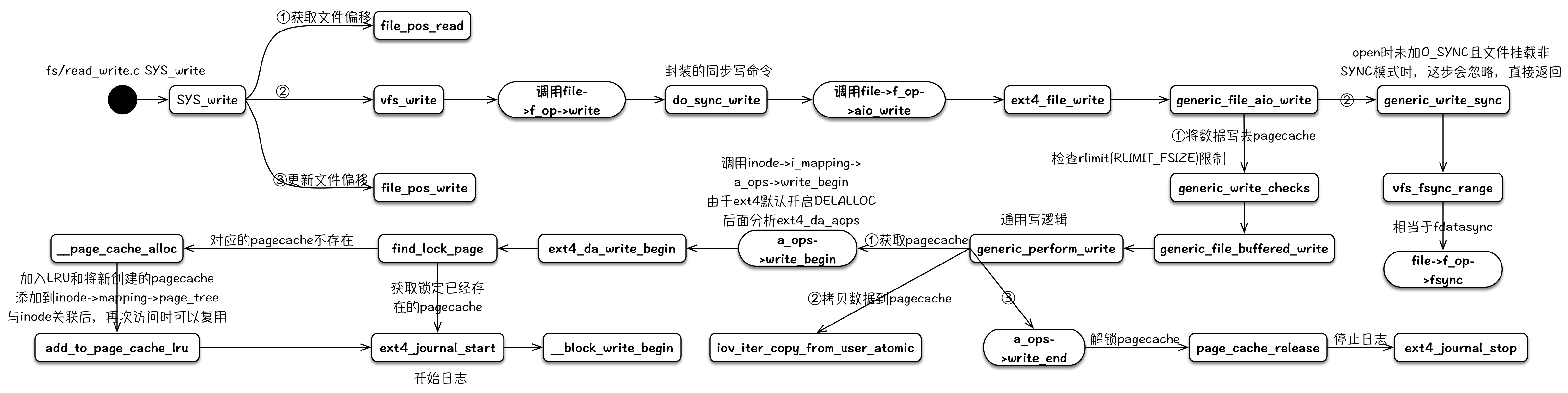
read
read 的读逻辑中包含预期 readahead 的逻辑,其可以通过与 fadvise 的配合达到文件预取的效果。这部分的代码分析可以参考:《Linux 内核读文件过程》
其整个内核逻辑流程可以用下图来表示:
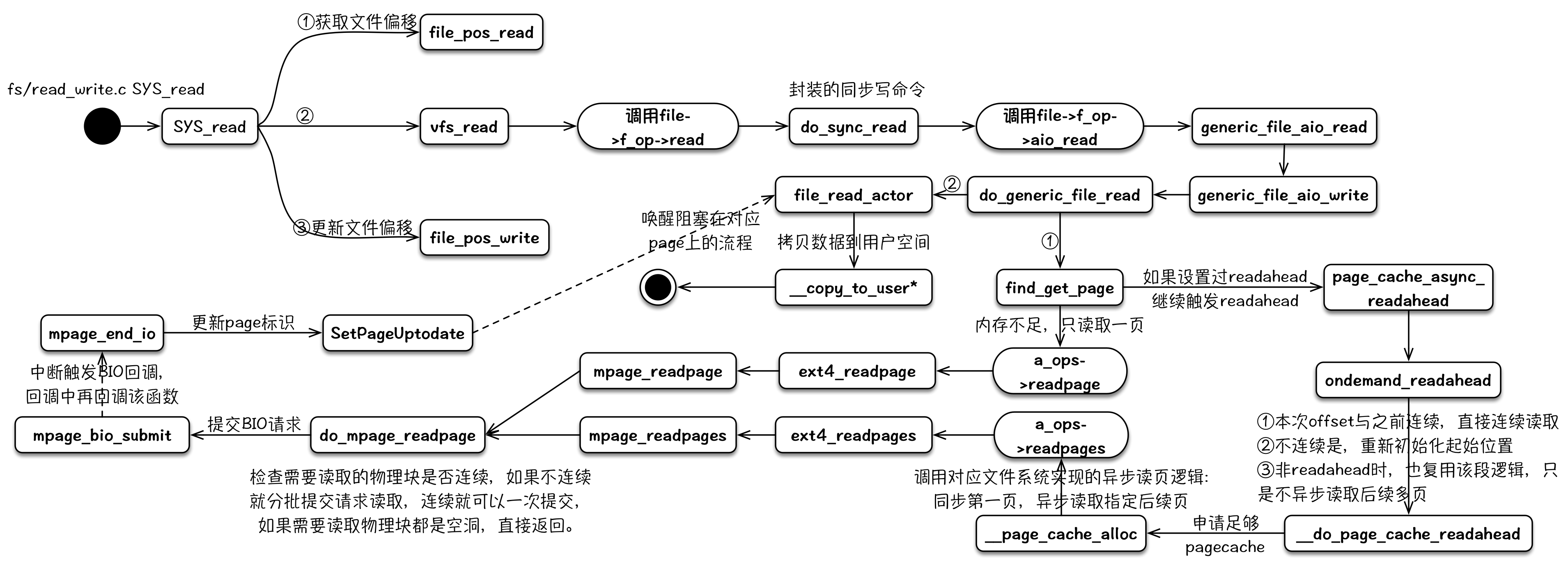
fwrite & fflush & fsync
fwrite & fflush:标准 IO 函数(如 fread,fwrite 等)会在内存(用户空间)中建立缓冲,该函数刷新用户空间的内存缓冲,将内容写入内核缓冲,要想将其真正写入磁盘,还需要调用 fsync。(即先调用 fflush 然后再调用 fsync,否则不会起作用)。fflush 以指定的文件流描述符为参数(对应以 fopen 等函数打开的文件流),仅仅是把上层缓冲区中的数据刷新到内核缓冲区就返回。
write 函数,默认使用 Buffered IO 方式,该函数只是把用户 buff 内的数据写入文件的页缓存(page cache)
sync 函数只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。通常称为 update 的系统守护进程会周期性地(一般每隔 30 秒)调用 sync 函数。这就保证了定期冲洗内核的块缓冲区。命令 sync(1)也调用 sync 函数。
fsync 函数只对由文件描述符 filedes 指定的单一文件起作用,并且等待写磁盘操作结束,然后返回。 fsync 可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上。
fdatasync 函数类似于 fsync,但它只影响文件的数据部分。而除数据外,fsync 还会同步更新文件的属性。对于提供事务支持的数据库,在事务提交时,都要确保事务日志(包含该事务所有的修改操作以及一个提交记录)完全写到硬盘上,才认定事务提交成功并返回给应用层。
下图中的 stdio buff 即 fwrite 在用户空间使用的缓冲: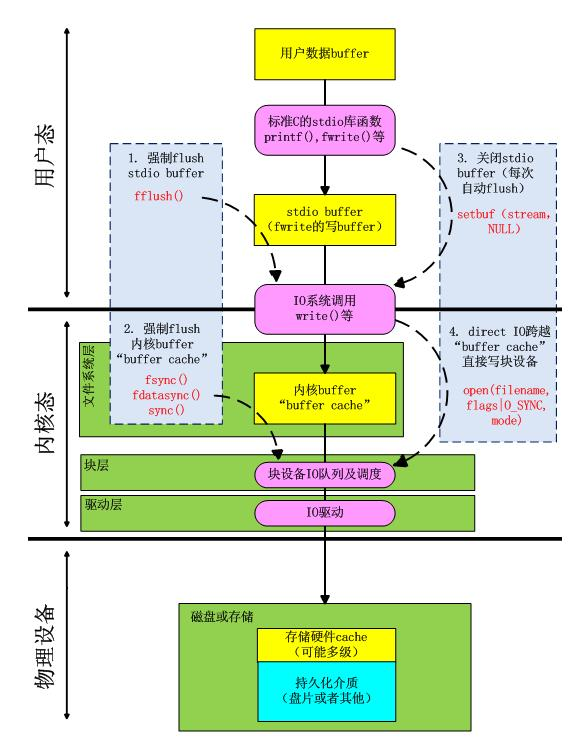
借助 GDB 即可看到 fflush 时的调用栈:(gdb) bt
#0 0x00007ffff72e0840 in **write** () from /lib64/libc.so.6
#1 0x00007ffff726cfb3 in _IO_new_file_write () from /lib64/libc.so.6
#2 0x00007ffff726e41c in __GI__IO_do_write () from /lib64/libc.so.6
#3 0x00007ffff726c810 in **__GI_****_IO_file_sync** () from /lib64/libc.so.6
#4 0x00007ffff72620a2 in **fflush** () from /lib64/libc.so.6
#5 0x00000000004007bd in main () at ggg.cpp:12
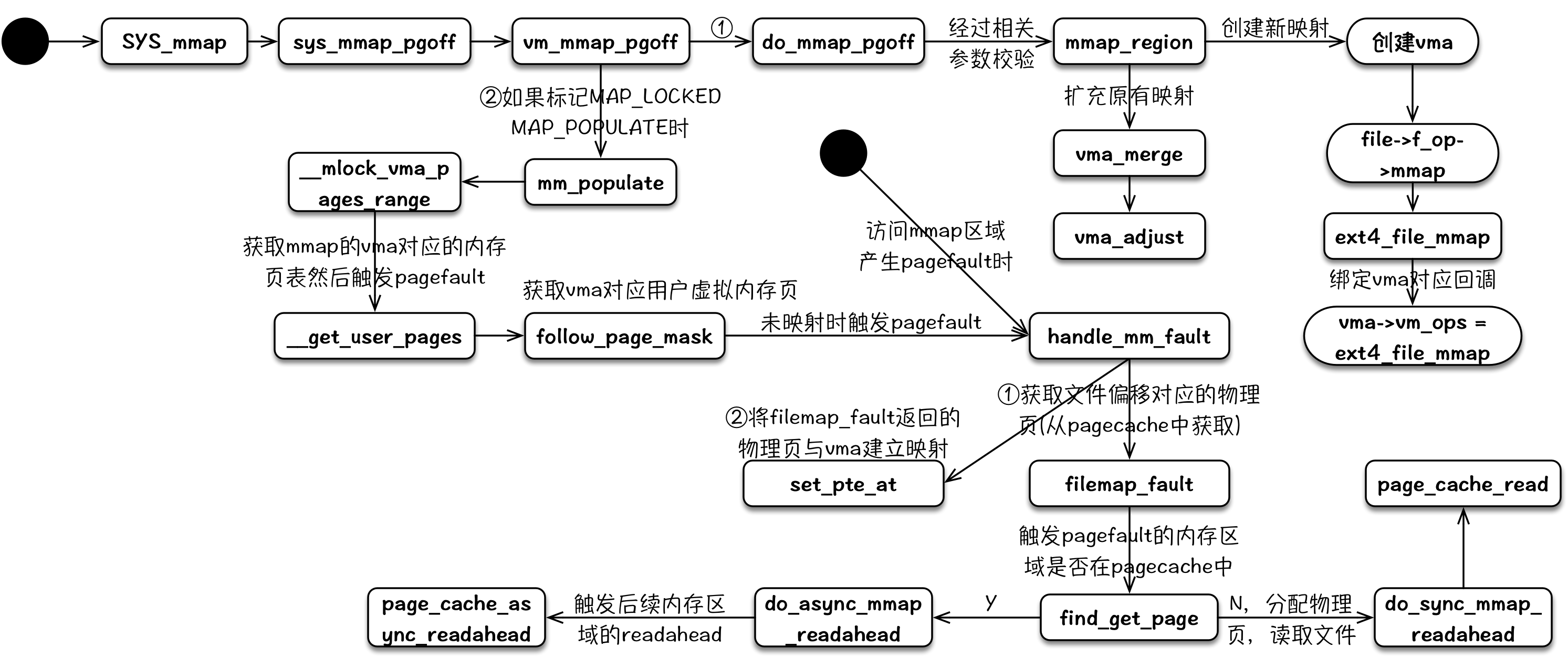
mmap
用户调用 mmap 将文件映射到内存时,内核进行一系列的参数检查,然后创建对应的 vma,然后给该 vma 绑定 vma_ops。当用户访问到 mmap 对应的内存时,CPU 会触发 page fault,在 page fault 回调中,将申请 pagecache 中的匿名页,读取文件到其物理内存中,然后将 pagecache 中所属的物理页与用户进程的 vma 进行映射。
其整个内核逻辑流程可以用下图来表示,其中 page fault 部分比较简略,可以参考 Linux Page Fault(缺页异常):
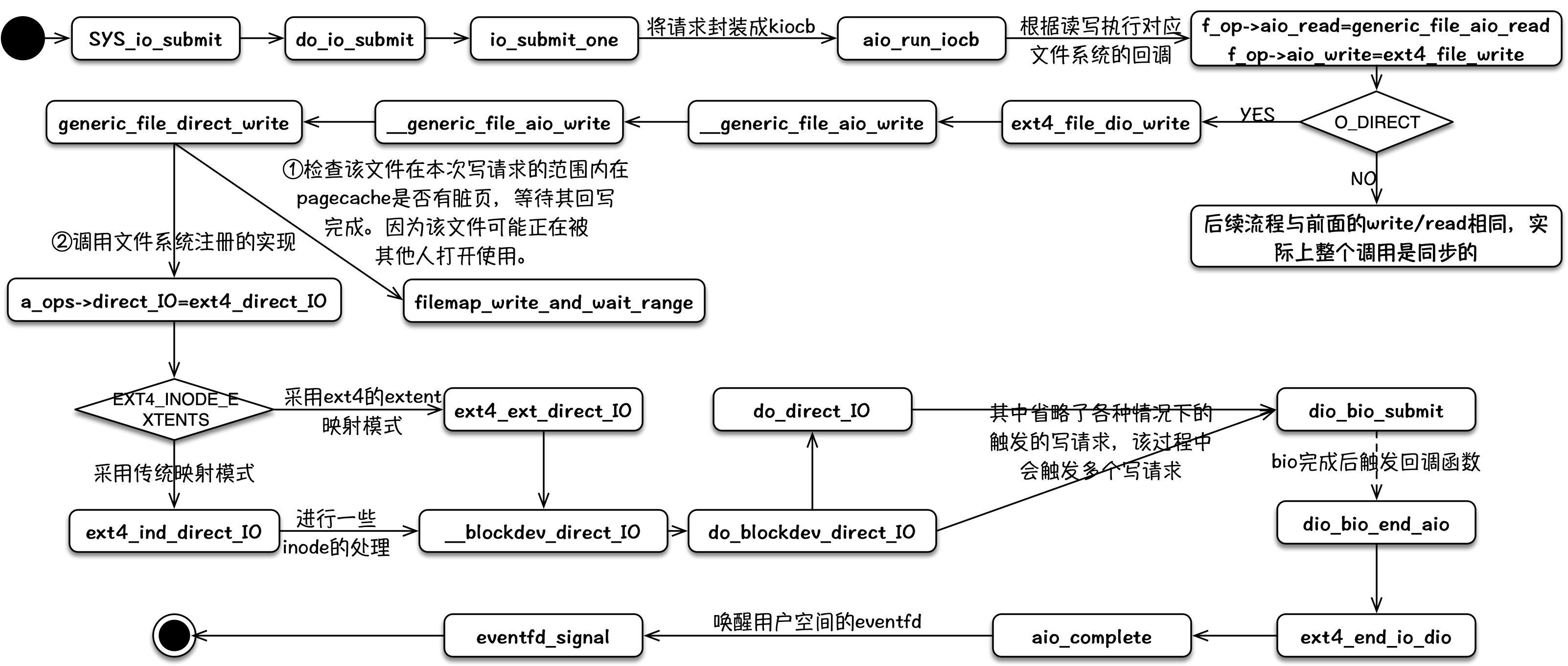
io_submit
对于非 O_DIRECT 标记打开的文件,其内部逻辑与 write 流程基本一致,最终将数据拷贝到 pagecache 中,整个调用实际都是同步阻塞的。
对于O_DIRECT标记打开的文件,在文件系统层(vfs/ext4等)仍然是同步的,在一些文件系统日志、文件系统数据块与磁盘映射、bio 请求队列满等情况下,仍然会被同步阻塞。当经过文件系统层后,被封装成一个bio请求时,且 bio 请求队列未满时,该请求进入 bio 请求队列后即刻返回,从而形成一个异步写事件。
目前异步 IO 使用最多的是 linux native aio,不幸的是,其存在着诸多约束(io_uring 新异步 IO 机制,性能提升超 150%,堪比 SPDK):
- 最大的限制无疑是仅支持 direct io。而
O_DIRECT存在 bypass 缓存和 size 对齐等限制,直接影响了 aio 在很多场景的使用。而针对 buffered io,其表现为同步。 - 即使满足了所有异步 IO 的约束,有时候还是可能会被阻塞。例如,等待元数据 IO,或者等待 block 层 request 的分配等。
- 存在额外的拷贝开销,每个 IO 提交需要拷贝 64+8 字节(
iocb64 字节,iocbpp指针 8 字节),每个 IO 完成需要拷贝 32 字节,这 104 字节的拷贝在大量小 IO 的场景下影响很可观。同时,需要非常小心地使用完成事件以避免丢事件。 - IO 需要至少 2 个系统调用(submit + wait-for-completion),这在 spectre/meltdown 开启的前提下性能下降非常严重。