@toc:
- NIO API(Channel/Buffer/Selector, 网络/文件/堆外内存)
- NIO 高性能的实现(异步非阻塞 I/O + 堆外内存)
- 网络编程中两种高性能 I/O 设计模式(多路复用):Reactor 和 Proactor
从 BIO 到 NIO
BIO 即阻塞 I/O,不管是磁盘 I/O 还是网络 I/O,数据在写入 OutputStream 或者从 InputStream 读取时都有可能会阻塞。一旦有线程阻塞将会失去 CPU 的使用权,这在当前的大规模访问量和有性能要求情况下是不能接受的。
Java NIO 是 java 1.4 之后新出的一套 IO 接口,这里的的新是相对于原有标准的 Java IO 和 Java Networking 接口。NIO 提供了一种完全不同的操作方式。
NIO(Non-blocking I/O)是一种同步非阻塞的 I/O 模型,也是 I/O 多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O 处理问题的有效方式。
NIO 包介绍
Java Non-blocking I/O 主要有三大核心部分:Channel (通道),Buffer (缓冲区), Selector;
除此之外,Java NIO 还包括了新的文件/目录的操作: Path 和 Files。
- java.nio.channels 包:
java.nio.channels.ServerSocketChanneljava.nio.channels.SocketChanneljava.nio.channels.FileChannel
java.nio.channels.SocketChannel.Selector类- java.nio.Buff 接口:
java.nio.ByteBuffer: 最基本的字符 buff, 从Channel(ServerSocketChannel, FileChannel 等)读取出的内容放在ByteBuffer里, 或者通过Channel.write把 ByteBuffer 内容写入 Channel;DirectByteBuffer: JVM 堆外分配;java.nio.MappedByteBuffer: MappedBuffer 是通过内存文件映射将文件中的内容直接映射到堆外内存中,其本质也是一个 DirectBuffer;HeapByteBuffer: JVM 堆内分配;
- java.nio.file 包:
java.nio.file.Path: Path 的实例指代一个目录或文件java.nio.file.Paths: Path 的工厂类, 用于获取 Path 实例java.nio.file.Files: 提供对Path的操作
▶ BIO 和 NIO 的对比变化如下:
- (1) BIO 流 vs NIO 管道:
- Java BIO 的各种流的读写都是阻塞操作。这意味着一个线程一旦调用了 read(),write()方法但系统缓冲区没数据可读,那么该线程会进入阻塞状态(Blocked)。
- NIO 读写都是非阻塞的, NIO 基于 Channel(管道)和 Buffer(缓冲区)进行操作:数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Channel 可以是文件也可以是 Socket;
- (2) NIO 里新增了 Selector,用于监听多个 Channel 的事件,当 Channel 产生可读写事件后, 用 ByteBuffer 读取数据。
Selector 允许一个单一线程监听多个 Channel 输入。我们可以注册多个 Channel 到 Selector 上,然后然后用一个线程来挑出一个处于可读或者可写状态的 Channel。Selector 机制使得单线程管理过个 Channel 变得容易。 - (3) NIO 的提供了
Path和Files来取代 io 包中的File,Path的实例指代一个目录或文件,Files则提供了对目录或文件的基本操作(exists, copy, move, delete)
NIO ByteBuffer
ByteBuffer (参考官方文档 Buffer (Java Platform SE 8 ) )的属性、方法:
使用Buffer读写数据一般遵循以下四个步骤: |
ByteBuffer.allocate(int): 创建 buff 并初始化大小put(byte),put(byte[]): 向 buff 存储数据get(), 返回 position 位置的一个 byte属性 capacity >= limit >= position >= mark
capacity: 指定数组大小, Buffer 创建后就不可改变;position: 下一个要读或要写的位置, 初始值 0, 每次写入 or 读取一个字节 position++limit: 缓冲区的终点, 不可操作 limit 后面的元素,- buffer 刚创建还未写入数据时, limit 初始值等于 capacity,
- 开始写数据, position ++
- 开始读数据, 调用 flip()方法后 limit=position, 然后 position=0, 意思是 buff 可读取的范围是 position~limit
mark: 初始值-1, 备忘位置, 参见 mark()/reset()方法
flip(): 向 Buffer 写完数据, 开始读数据前要调用一次, 把 position 的值赋给 limit, 然后 position=0, 然后可以调用 get()从 position 读出字节, 读的上限是在 limit 处;clear(): limit 置为 capacity, position 置为 0, mark 置为-1, 这时可以写 buffer 了;compact(): 清除读过的数据, 将所有未读的数据拷贝到 buffer 起始处, position 指向未读的末尾, limit 置为 capacity, 又可以再次对 buffer 进行写入了;rewind(), position=0, mark=-1, 不改变 limit 的值, 可以再读一遍[0~limit]的字节mark(): 调用后, 使 mark=position, 使用mark()来记录当前 positionreset(): 调用后, 使 position=mark, 使用 reset()让 position 置为 mark 的值, 一次 reset()对应一次 mark()equals(): 比较两个 buff 剩余未读的字节数, 比较剩余的每一个字节compareTo(): ..

图来自 https://www.baeldung.com/java-bytebuffer
ByteBuffer 内部是由一个数组实现的, 所以 capacity 理论最大值受
MAX_Integer和-Xmx限制
NIO Channel
@todo
NIO Selector
@todo
Files & Path
示例代码:
public class NioPathAndFiles { |
NIO 网络读写
API 说明:
- 服务端:
ServerSocketChannel.open(): 创建一个 server socket channel 实例, 相当于传统 Socket 的ServerSocketServerSocketChannel.socket().bind(SocketAddress local): 绑定端口ServerSocketChannel.configureBlocking(false): 把 server socket channel 设置为 非阻塞 的情况下,accept()/read()/write()会立刻返回;ServerSocketChannel.accept(): 阻塞, 并在有客户端成功连接时返回一个SocketChannel实例ServerSocketChannel.register(Selector, EVENT): 为 server channel 注册监听的事件
- Selector:
Selector.open(): 创建一个 selector 实例Selector.select(): 开始监听并阻塞
- 客户端:
SocketChannel.configureBlocking(false): 把 socket channel 设置为非阻塞, 读写会立刻返回SocketChannel.write(ByteBuffer): 写方法SocketChannel.read(ByteBuffer): 读方法, 返回值是读取的字节数
用 NIO API 实现简单的 Socket Server(用 Selector 实现多路复用, 用 Channel.configureBlocking(false) 设置为非阻塞 I/O):
ByteBuffer echoBuffer = ByteBuffer.allocate(1024); |
总结: NIO 的 Socket 多路复用如下:
- 创建服务端 socketChannel
- 创建 Selector
- 服务端 socketChannel 在 Selector 上注册 ACCEPT 事件
- While 循环
- selector.select() 阻塞, 如果 Selector 上有事件发生, 退出阻塞
- selector 取出所有事件集合, 并遍历
- 如果有 ACCEPT 事件, 服务端 socketChannel 去 accept 这个请求, 创建客户端 socketChannel, 并在 Selector 上注册该 channel 的 READ 事件
- 如果有 READ 事件, 读对应的客户端 socketChannel
与传统 Socket 比较
从上面的代码可以看到,
- 传统的 Java Socket(BIO, 阻塞 IO), 等同于
java.net + java.io, 使用的”Socket 句柄”是java.net.ServerSocket(服务端 socket)和java.net.Socket(客户端 socket), 通过Socket获取 InputStream/OutpubtStream 进行读/写. - NIO Socket 使用的”socket 句柄”是
java.nio.channels包下面的ServerSocketChannel和SocketChannel, SocketChannel 的读写是通过java.nio.ByteBuffer - 前者 IO 方法是阻塞的, 后者 IO 方法是非阻塞 // ?
多线程-BIO 缺陷
- 线程的创建和销毁成本很高
- 线程本身占用较大内存,像 Java 的线程栈,一般至少分配 512 K~1 M 的空间,如果系统中的线程数过千…
- 线程的切换成本是很高
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或 CPU 核心数,高并发下会使系统负载压力过大
BIO(阻塞 IO)模型,之所以需要多线程,是因为在进行 I/O 操作的时候,一是没有办法知道到底能不能写、能不能读,只能阻塞等待。
NIO 的读写函数可以立刻返回,这就给了我们不开线程利用 CPU 的最好机会:如果一个连接不能读写(socket.read()返回 0 或者 socket.write()返回 0),我们可以把这件事记下来,记录的方式通常是在 Selector 上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
NIO 由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(没有可干的事情必须要阻塞),剩余的 I/O 操作都是纯 CPU 操作,没有必要开启多线程。
单线程处理 I/O 的效率确实非常高,没有线程切换,只是拼命的读、写、选择事件。
以上参考: Java NIO浅析 - @ref
NIO 大文件读写
大文件读写几种方案:
- 传统 IO 读取方式:
- 字节方式读取: FileInputStream VS BufferedInputStream
- 字符方式读取: BufferedReader
- NIO 读取:
- FileChannel + ByteBuffer
- MappedByteBuffer(内存映射)
测试结论参考: JAVA NIO(六):读取10G的文件其实很容易 - CSDN博客 @ref
传统 NIO 读取:
java.io.RandomAccessFile 提供了文件随机读写,
下面的代码是使用 nio 中的 FileChannel 和 ByteBuffer 从 RandomAccessFile 中读取:
RandomAccessFile randomAccessFile = new RandomAccessFile(new File(filePath), "r"); |
使用内存映射:
nio.FileChannel 还提供了内存映射的方式读取文件:
RandomAccessFile randomAccessFile = new RandomAccessFile(new File(filePath), "r"); |
内存映射读取的优劣
- 内存映射方式的读取速度更快
- read()是系统调用, 首先将文件从硬盘拷贝到内核空间的一个缓冲区, 再将这些数据拷贝到用户空间, 实际上进行了两次数据拷贝.
- map()也是系统调用, 但没有进行数据拷贝, 当缺页中断发生时, 直接将文件从硬盘拷贝到用户空间, 只进行了一次数据拷贝.
- MappedByteBuffer 使用虚拟内存, 因此分配(map)的内存大小不受 JVM 的-Xmx 参数限制, 但是也是有大小限制的;
- 如果当文件超出1.5G 限制时, 可以通过 position 参数重新
map(mode, position, size)文件后面的内容; - MappedByteBuffer 在处理大文件时的确性能很高, 但也存在一些问题, 如内存占用/文件关闭不确定, 被其打开的文件只有在垃圾回收的才会被关闭, 而且这个时间点是不确定的。javadoc 中也提到:”A mapped byte buffer and the file mapping that it represents remain* valid until the buffer itself is garbage-collected.”
参考: 深入浅出 MappedByteBuffer v
堆外内存
堆外内存就是把内存对象分配在 Java 虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
堆外内存默认是和 -Xmx 默认一样大,也可以使用 -XX:MaxDirectMemorySize 指定堆外内存大小
堆内 vs 堆外
- 堆外内存减少了堆内内存的垃圾回收, 减少 STW 停顿;
- 使用 Java 的 堆内内存 进行 IO 操作, 会比 C Native 的程序多一次内存拷贝。为什么呢?
Java 的 IO 底层也是调用了 C Native 的
read()/write()函数, 这些函数需要传入void *类型的内存地址, 并且这个内存地址指向的内容不能被改变, 否则read()/write()操作的内存就错了;
有些 GC 回收器会整理内存, Java 对象在内存的地址会被改变,
所以使用堆内内存进行 IO 操作, 需要先把堆内内容 copy 到 JVM 堆外的连续内存, 然后传递给 C 的read()/write(), 这就多了一次内存拷贝;
JVM 规范没有要求byte[]一定是物理连续的, 但是 C 里用malloc()分配的内存是连续的;
How to 创建堆外内存
三种方式创建堆外内存:
使用 NIO 提供的分配方法
ByteBuffer buf = ByteBuffer.allocate(1024); // 返回的是堆内的 HeapByteBuffer
ByteBuffer buf = ByteBuffer.allocateDirect(1024); // 返回的是直接堆外的 DirectByteBuffer使用 NIO 提供的堆外内存相关的类:
DirectByteBuffer,MappedByteBuffer// DirectByteBuffer
DirectByteBuffer dbf = new DirectByteBuffer(1024);
// MappedByteBuffer可以通过FileChannel实例获取, 用于文件内存映射直接使用 unsafe:
Unsafe unsafe = GetUsafeInstance.getUnsafeInstance();
long pointer = unsafe.allocateMemory(1024);
DirectByteBuffer 该类本身还是位于 Java 内存模型的堆中。
而 DirectByteBuffer 构造器中调用unsafe.allocateMemory(size)是个一个 native 方法,这个方法分配的是堆外内存,通过 C 的 malloc 来进行分配的。并不属于 JVM 内存。
堆外内存释放
- 通过堆内对象触发 GC, 堆内对象和指向的堆外内存一并被回收;
- 通过 Unsafe 回收;
public class FreeDirectMemoryExample |
堆外内存 GC
如果堆外内存容量超过了 -XX:MaxDirectMemorySize 会发生 OutOfMemoryError: Direct buffer memory,
如果 GC 回收了 DirectBuffer 对象,那么 DirectBuffer 对象指向的堆外内存,会在 GC 的后期被回收,
如果 Java 程序使用的堆内内存(Heap)占用率不高但是却大量使用 DirectBuffer 分配堆外内存,
这种情况下不会因为堆内内存触发 Full GC 也就无法自动释放堆外内存,
所以通常需要调用 System.gc() 来强制回收堆外内存(但是线上环境不建议这样触发 Full GC),这种情况下一定确保不能启用了 -XX:+DisableExplicitGC 导致 System.gc() 被禁用。
System.gc()会建议 JVM 进行 Full GC, 对新生代的老生代都会进行内存回收,这样会比较彻底地回收 DirectByteBuffer 对象以及他们关联的堆外内存.
DirectByteBuffer 对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为冰山对象.
JVM 发生 YGC(Young gc 很频繁, 会 STW, 但是 Copy GC 算法的 STW 极短)的时候会将新生代里的不可达的 DirectByteBuffer 对象及其堆外内存回收了,但是无法对 Old Gen 里的 DirectByteBuffer 对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题。( 并且堆外内存多用于生命期中等或较长的对象 )
如果有大量的 DirectByteBuffer 对象移到了 Old Gen,但是又一直没有做 Old Gen 的 CMS GC 或者 Gull GC,那么物理内存可能被慢慢耗光,但是我们还不知道发生了什么,因为 heap 明明剩余的内存还很多。
本章参考
NIO 高性能是如何实现的
(1)使用异步非阻塞实现高效的单线程轮询,避免阻塞式 IO 开多线程的方式。// NIO 由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(Selector),剩余的 I/O 操作都是纯 CPU 操作,没有必要开启多线程。并且由于线程的节约,连接数大的时候因为线程切换带来的问题也随之解决,进而为处理海量连接提供了可能。
NIO 的读写函数可以立刻返回(用
Channel.configureBlocking(false)设置该通道为非阻塞),如果一个连接不能读写(socket.read()返回 0 或者socket.write()返回 0),我们可以把这件事记下来,记录的方式通常是在 Selector 上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。Java 的
Selector:同一个 channel 的 select 不能被并发的调用。因此,如果有多个 I/O 线程,必须保证:一个 socket 只能属于一个 IoThread,而一个 IoThread 可以管理多个 socket。
(2)使用 DirectBuffer 减少 IO 时数据拷贝次数:
使用堆内内存的时候,比如我们要完成一个从文件中读数据到堆内内存的操作,调用
FileChannelImpl.read(HeapByteBuffer)实际上 File IO 会将数据读到堆外内存中,然后堆外内存再将这部分堆外数据拷贝到堆内内存。// 为什么 Java IO 会多一次内存拷贝? 因为系统调用 read & write 函数的参数 buf 必须指向不变的内存地址,Java 的堆内内存在 GC 过程中(带有 compact 的 GC)地址会被改变;如果直接使用堆外内存,如
DirectByteBuffer,这种方式是直接在堆外分配一个内存(即,native memory)来存储数据,程序通过 JNI, 直接将这部分的内存数据通过read()/write()到堆外内存中。
➤ 比较传统 IO
- NIO 提供了直接内存的 ByteBuffer, 相比堆内内存, 在 read/write 时使用直接内存可以减少一次内存拷贝 // 但 DirectByteBuffer 创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能
- NIO 多了非阻塞 IO + 多路复用 Selector(epoll 实现),Selector 可以使用一个线程即可管理大量 IO 连接的读写事件,对比 BIO (connection pre thread),节省了线程调度和切换的开销,更节省大量线程带来的内存消耗,
Reactor 三种常见线程模型
➤ 三种 Reactor 线程模型:
- 单 Reactor
- 单 Reactor + 多线程
- 主从 Reactor + 多线程
➤ Reactor & Proactor IO 模型中,涉及到的角色:
- Demultiplexer: 多路复用器, select or epoll 的抽象, 产生 IO 事件
- Dispatcher: 分发器, 将多路复用器产生的事件进行分发
- Acceptor: accept 事件处理器(函数)
- IOHandler: IO 事件处理器(函数)
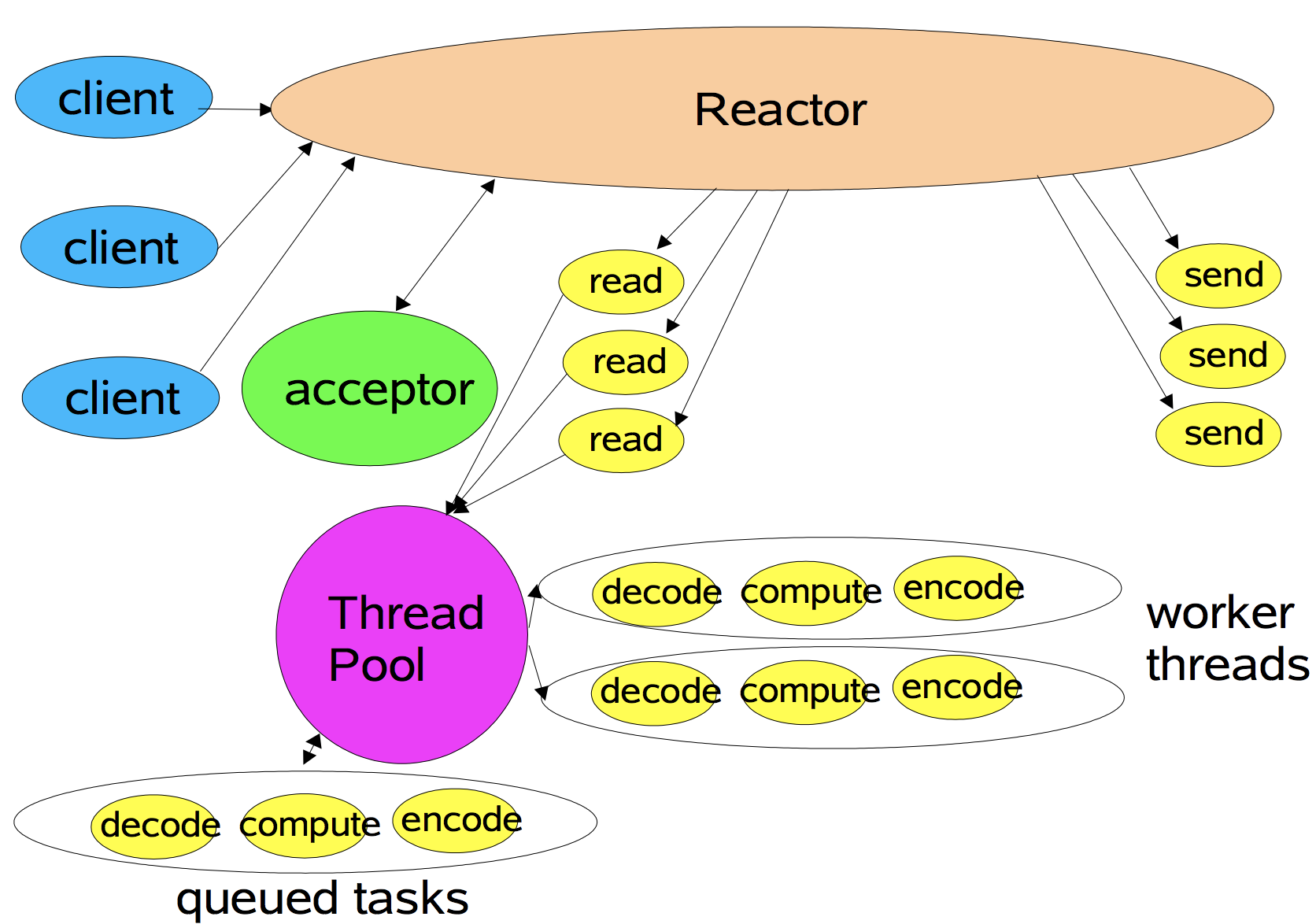
单 Reactor 模型
一个 Reactor Thread, 负责处理全部 I/O 事件(accept, read, send), 以及业务代码(decode, compute, encode)
- 在一个 Reactor Thread 里, select 监听 accept/read/write 事件, 事件由 Dispatcher 进行分发:
- 有 accept 事件, Dispatcher 分发给 Acceptor 进行握手/鉴权等处理;
- 有 read/write 事件, Dispatcher 分发给 IOHandler: 进行 read → decode → compute → encode → send ;
- 缺点: 当某个 Handler 阻塞时,会导致其他客户端的 handler 和 accpetor 都得不到执行,无法做到高性能,只适用于业务处理非常快速的场景

单 Reactor +多线程
一个 Reactor Thread, 负责处理全部 I/O 事件(accept, read, send), 但业务代码交给线程池处理..
- Reactor Thread 里, select 监听 accept/read/write 事件, 事件由 Dispatcher 进行分发:
- 有 accept 事件, 处理同单线程模型,Reactor 线程直接调用 acceptor 函数;
- 有 read 事件, Dispatcher 分发给 IOHandler 处理 (函数调用, 仍在 Reactor 线程里), 也就是在 Reactor 线程里进行非阻塞 read;
- 从 Worker Thread Pool 取出一个 Worker, 对读到的数据进行 decode → compute → encode 处理流程;
- Worker 的结果交还给 Reactor Thread, 由 Reactor Thread 进行 send;
- 比较单线程模型, 多线程 Reactor 模型仍在主线程里处理读/写操作, 不再处理业务代码, 业务代码交给线程池执行;
- 缺点: Reactor Thread 仍然负责全部的 accept/read/write 的处理, 如果在 Reactor Thread 进行有大量读写事件, 同时大量连接事件(在 accept 时进行鉴权等), 这时候仍会有单线程的瓶颈
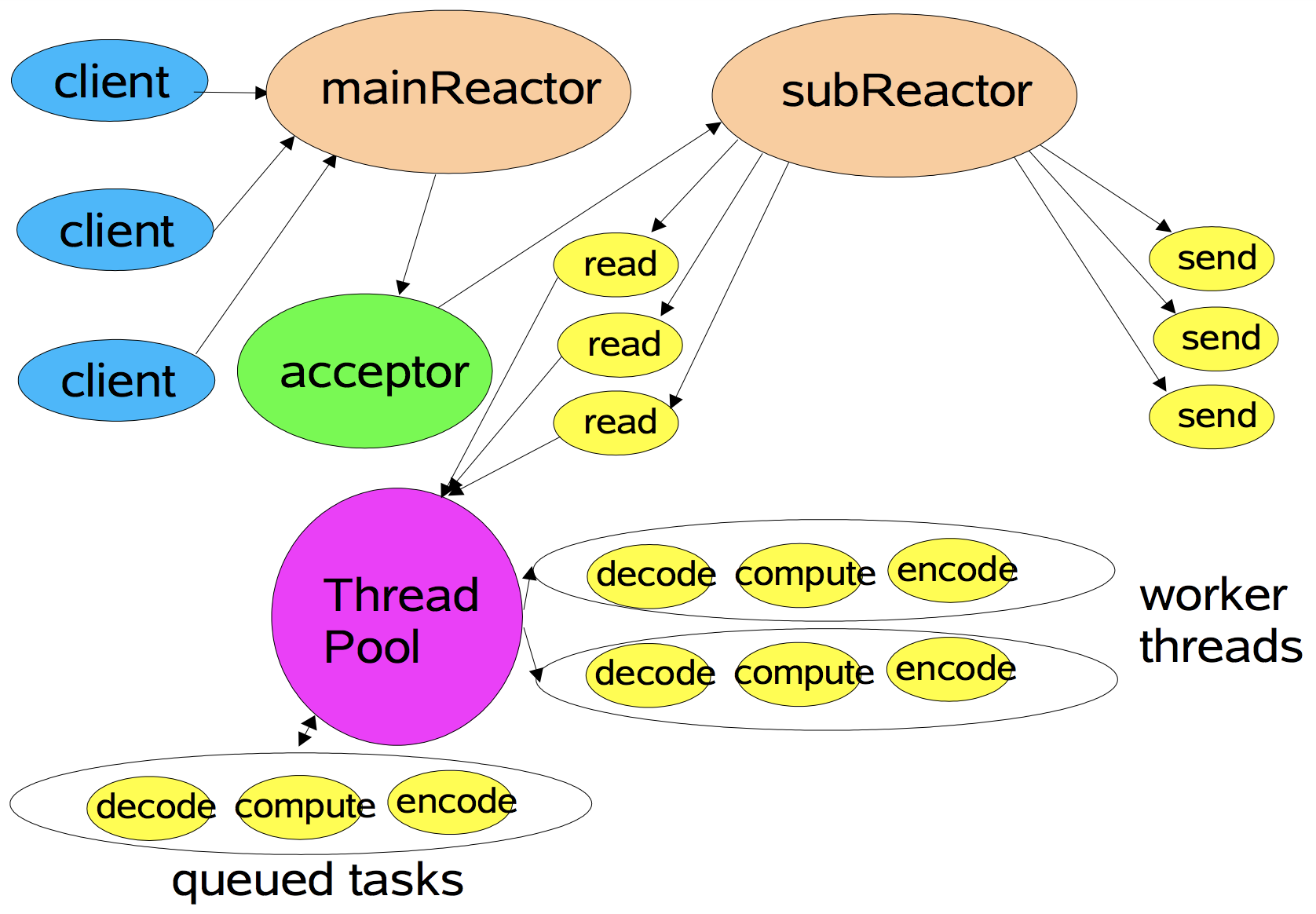
主从 Reactor + 多线程
不再是一个 Reactor Thread, 有 Main Reactor & Sub Reactor 两个线程, 分别处理 accept 事件 & IO 事件, 业务代码交给线程池处理
- Main Reactor Thread 的 Selector 负责监听 accept 事件, 交给 Acceptor 处理;
- Acceptor 接受请求之后创建新的 SocketChannel, 并处理鉴权/握手等;
- 完成上一步处理的 socket, 从 Main Reactor Thread 的 Selector 移除, 并注册到 Sub Reactor Thread 的 Selector 上;
- Sub Reactor Thread 的 Selector 负责监听这些 socket 的 IO (read)事件, 并调用 IOHandler 进行非阻塞 read;
- 从 Worker Thread Pool 取出一个 Worker, 对读到的数据进行 decode → compute → encode 处理流程;
- Worker 的结果交还给 Reactor Thread, 由 Reactor Thread 进行 send;
@ref: [[../_attachments/Scalable IO in Java - Doug Lea.pdf]]
Netty 实现多线程 Reactor
➤ Netty 中重要的 API 类:
NioEventLoop: 是 Netty 的 Reactor 线程
- 继承自 SingleThreadEventExecutor, 只有一个线程的线程池
- 每个 NioEventLoop 都有一个 Selector(封装了 epoll), 可以用来监听 accept/r/w 事件
NioEventLoop 的职责:
1. 作为服务端 Acceptor 线程,负责处理客户端的请求接入; 2. 作为客户端 Connecor 线程,负责注册监听连接操作位,用于判断异步连接结果; 3. 作为 IO 线程,监听网络读操作位,负责从 SocketChannel 中读取报文; 4. 作为 IO 线程,负责向 SocketChannel 写入报文发送给对方,如果发生写半包,会自动注册监听写事件,用于后续继续发送半包数据,直到数据全部发送完成; 5. 作为定时任务线程,可以执行定时任务,例如链路空闲检测和发送心跳消息等; 6. 作为线程执行器可以执行普通的任务线程(Runnable)。
NioEventLoopGroup: 一个 NioEventLoopGroup 管理多个 NioEventLoop, 构造函数可以指定管理 NioEventLoop 的个数, 如果没有设置,默认取 -Dio.netty.eventLoopThreads,如果该系统参数也没有指定,则为可用的 CPU 内核数 × 2。
Channel(NioServerSocketChannel):类似 NIO 中的 channel,对 socket 的封装,包括 connect、bind、read、write,此外 Nio 的 Channel 还包括一个 ChannelPipeline 成员;
ChannelPipeline:该 Channel 上的读写操作,都会走到这个 ChannelPipeline 中,pipeline 上可以添加(事件,ChannelHandler),当 channel 上完成 register、active、read、readComplete 等事件时,会触发 pipeline 中的相应的 ChannelHandler;如同名字一样,pipeline 串行执行这些 Handler;
EventLoop 串行执行 pipeline 上的 Handler: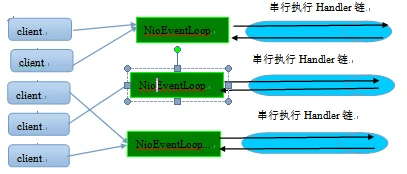
➤ 用 Netty 实现多线程 Reactor(伪码),这里使用的是主从 Reactor + 多线程模型:
NioEventLoopGroup bossGroup = new NioEventLoopGroup(1); // 主Reactor线程 |
- Netty Server 创建两个
NioEventLoopGroup: bossGroup(main Reactor) 和 workerGroup(sub Reactor);
- bossGroup 线程组通常只有一个
EventLoop线程(Boss 线程), 这个线程作为 Main Reactor Thread, 负责 select 监听端口的 accept 事件并进行后续处理(创建 SocketChannel.. );
- bossGroup 的
EventLoop线程会把创建的 SocketChannel, 顺序分发给 workerGroup 线程组中的每一个 Worker 线程(类似轮询);
- workerGroup 线程组, 通常包含 cpu core 数量的 1-2倍个
EventLoop线程(Worker 线程), 这些 Worker 线程作为 Sub Reactor Threads, Worker 线程内使用 Selector 监听 SocketChannel 的读写事件;
- childHandler 是传入了一个 ChannelInitializer,这是当有新的客户端连接到达时会回调的一个方法。我们给这个新的 channel 的 pipeline 上添加了一个处理器 serverHandler,当收到数据的时候会执行该 handler
@ref:
- Netty系列之Netty线程模型 - InfoQ
- 聊聊Netty那些事儿之从内核角度看IO模型
- 剖析Netty内部网络实现原理
- 一文聊透 Netty 核心引擎 Reactor 的运转架构 - bin的技术小屋 - 博客园
Java 对 AIO 的支持
AIO(asynchronous I/O): 异步 IO, java.nio.channels包做了支持, 包括: AsynchronousSocketChannel / AsynchronousServerSocketChannel / AsynchronousFileChannel