数据类型
基本数据类型
Java的基本类型有: char(2字节), byte(1字节), short(2字节), int(4字节), long(8字节), float(4字节), double(8字节), boolean(-),
Java没有bit类型, 但可以使用BitSet类代替.
- byte: 1字节, 范围-128~127
- short: 2字节, 范围-32768~32767, 为什么最小是-32768 ?
- int/long:
100L表示long类型, 0x/0/0b前缀分别表示16/8/2进制- 如果
long l = 3600 * 24 * 30 * 1000,1000后面不加L,右边会按int计算并产生溢出
- 如果
- float/double: 3.14F表示float类型, 3.14和3.14D都表示double
- char: 单引号, ‘\u2122’或’A’
浮点数的比较
浮点数(基本类型)之间是否相等不能用==来比较,浮点数(包装数据类型)不能用 equals 来判断。
// 反例1: |
BitSet
BitSet bits = new BitSet(16); // 初始大小对性能的影响 |
包装器
包装器API
基本类型对应包装器为 Character, Byte, Short, Integer, Long, Float, Double, 包装器与基本类型互转:
Integer ii = Integer.valueOf(1); |
Integer 的相等比较:
- 如果比较 2 个 Integer 的值,需要用
equals而不是==
Float 的相等比较:
- 计算 abs(f1 - f2) ,然后与一个极小 diff 比较
Integer 和 Long 不同类型慎用 equals!详见 Long.equals 的解析
Double类的一些方法:
Double.compareTo(Double): 大于小于直接比较, =的判断是把double转成一个LongBit? Native方法, 需要看一下浮点数的内存isNaN()返回true表示不是正常数字, 比如除以0, 负数的平方根. 代码里如何得到一个NaN?
装箱拆箱的实现
▶ 何时发生装箱/拆箱:
- 什么是自动装箱: int → Integer, 实际调用
Integer.valueOf(int) - 什么时候发生自动装箱:
- 创建对象:
Integer i = 3 - 方法参数传递:
void method(Integer i)
- 创建对象:
- 什么是自动拆箱: Integer → int, 实际调用
integer.intValue() - 什么时候发生自动拆箱:
- 加法:
integer1 + integer2, 先拆箱转换为int … - 需要注意的是
if (integer3 == integer1 + integer2), 首先右边1和2拆箱为int, 变成if (integer3 == int), 这时不是发生(int→integer)装箱, 而是继续拆箱, 最终比较的是if (int == int)
- 加法:
▶ Integer/Long自动装箱 valueOf(x)的实现
- Integer/Long 的
valueOf(i)使用了享元模式, 在static代码块中预先创建了范围-128~127的对象, 缓存在数组型的 Cache(Integer[] cache)里; - 当调用
valueOf(i)的时候,先判断i的范围是否是-128~127,如果是则直接从cache里返回对象,减少类的创建; - 下面创建Integer的效率, 前者可能更高:
Integer i = 3,Integer i = new Integer(3); 为什么? - Float/Double的
valueOf(f)没有使用享元模式;
▶ 代码example
Long l1 = Long.valueOf(128); |
输出: false, true, false, true
慎用 Long.equals()
以下代码会输出false:
System.out.println(new Long(1).equals(1)); |
原因是,Long.equals(Object),进入equals是会对整形参数1进行一次装箱,i被包装成Integer(1),
和其他类的equals行为一样,Long.equals(Integer(1))会先判断输入参数的类型if (obj instanceof Long),这里就返回false了。
所以用Long的正确条例是,Long的方法传参数都用明确的long型:new Long(1L), longObj.equals(1L)。
BigInteger, BigDecimal
Java还提供了两个用于大数运算的类: BigInteger(任意大整数)和BigDecimal(任意大小的带小数点的数字). 常用方法: add(), subtract(), multiply(), divide()
BigInteger big1 = new BigInteger("99"); |
BigDecimal 的等值比较应使用 compareTo()方法,而不是 equals()方法。 说明:equals()方法会比较值和精度(1.0 与 1.00 返回结果为 false),而 compareTo()则会忽略精度。
数组
- Java中数组本质上也是对象, 拥有所有Object的方法, 不同于int/double等基本类型.
- Java 对象在内存里前几个字节是”对象头”, 非数组对象的的对象头占用2字节, 数组对象的对象头占用3字节, 多的1字节用来存储对象长度
- 数组可以通过属性
length获取长度, 遍历数组:for(int i = 0; i < array.length; i++)
- 数组创建后会记住元素类型和大小, 所以:
A[]类型的数组可以强转换为Object[], 但不能反过来执行;- 用
new A[1]方式创建的数组, 只能向内存储A类型或者A的派生类的对象, 试图存入其他类型对象会抛 ArrayStoreException; - 数组创建后不再能改变长度;
▶ 数组如果作为形参 or 返回值, 可以使用Object, 而不是用Object[] :
// 反射方式创建新数组 |
▶ 数组与list互转:
//list -> array |
Arrays
Java核心类库有两个Arrays类:
java.lang.reflect.Array: 提供了数组的反射相关方法;java.utils.Arrays: 类似Collections类, 提供了merge/sort等方法
示例代码: 用反射创建数组, 拷贝数组:
// java.lang.reflect.Array创建数组 |
java.util.Arrays
java.util.Arrays 包含了许多处理数组的实用方法:
asList: 将一个数组(变长参数的语法糖实现就是数组)转变成一个List(确切的来说是ArrayList),注意这个List是定长的,企图添加或者删除数据都会报错(java.lang.UnsupportedOperationException).List<Integer> list = Arrays.asList(3,4,2,1,5,7,6);
// 下面这种用法是错误的:
int a[] = new int[]{1,2,5,4,6,8,7,9};
List list = Arrays.asList(a);sort: 对数组进行排序。适合byte,char,double,float,int,long,short等基本类型,还有Object类型(实现了Comparable接口),如果提供了比较器Comparator也可以适用于泛型。void sort(Object[] a); // 需要类实现Comparable接口
void sort(T[] a, Comparator<? super T> c); // 带比较器binarySearch: 通过二分查找法对已排序(譬如经过Arrays.sort排序,且按照升序进行排序。如果数组没有经过排序,那么检索结果未知)的数组进行查找。适合byte,char,double,float,int,long,short等基本类型,还有Object类型和泛型copyOf: 数组拷贝,并返回新数组,底层采用System.arrayCopy(native方法)实现。copyOfRange: 数组拷贝,指定一定的范围,String str2[] = Arrays.copyOfRange(arr,1,3);equals和deepEquals:- equals:判断两个数组的每一个对应的元素是否equals
- deepEquals:主要针对一个数组中的元素还是数组的情况
toString和deepToString: 参考equals和deepEqualshashCode和deepHashCode:- hashCode:计算一个数组的hashCode. 每个元素的
element.hashCode()都要参与计算
- hashCode:计算一个数组的hashCode. 每个元素的
fill: 给数组赋值。填充数组。Arrays.fill(intArr, 1);
Java.lang.reflect.Array
施工中
枚举
- Java在SE5中才添加了emum特性, 在定义一个enum时会自动创建
toString()和value()方法(均是static方法), enum还支持类似Objec的私有属性,和构造;- enum 类型不支持
public和protected修饰符的构造方法, 因此构造函数一定要是private或friendly的. 也正因为如此, 所以枚举对象是无法在程序中通过直接调用其构造方法来初始化的. - 枚举可以出现在switch语句中, 若要判断两个枚举类型常量的值是否相等, 使用
==, 或equals()都可以. 前者更好因为可以可以判断null的情况 - 比较两个枚举类型常量的值的大小要使用
compareTo()方法.
- enum 类型不支持
// 一个基本的枚举: |
运算符
- 类实例的赋值操作
a=b实际是把 b 这个”对象引用”指向了 a 的指向的对象, 如果 b 原来的对象的引用数为0, 在一定条件下会被 JVM 销毁. - 对于基本数据类型,
==判断的是值, 而不是”是否指向同一个引用”; - 用
==比较Object, 如果a和b是否指向的是同一块内存则为true - 判断两个字符串的内容是否相同不能用
if(str1==str2), 要用str1.equals(str2)方法. - 大部分jdk中的类实现了
Object.equals(Object)这个方法(判断两值是否相等), 但是对于某些自定义的类要留意其equals方法, 因为Object.equals默认行为是比较引用的this==obj;
hashCode和equals更多参考: (五)面向对象
左右结合
Java中赋值=, 单目运算++等, 条件运算符?:是右结合, 其他都是左结合,
比如x=y=z, 相当于x=(y=z)
位移运算
- 左移<< : 丢弃最高位(符号位同样丢弃), 0补最低位. 当byte和short左移时, 自动升级为int型.
- 数学意义: 左移n位相等于乘以2^n
- 右移>> : 高位补充符号位, 正数右移补充0, 负数右移补充1, 当byte和short右移时, 自动升级为int型.
- 数学意义: 右移n位相当于除以2^n
- 无符号右移>>> : 无论正负, 高位补充0
- 无符号右移只是对32位和64位的值有意义
关于补码/反码参考脚注1
java.lang.Math
- abs:
return v>0?v:-v; - sqrt: native
- pow: native
控制流程和语句
- Java的
if,for,while,do-while,if...else if和C++完全一样, 此外Java还多了foreach:for(int i : integerArray) {...} switch语句支持String类型和enum类型
方法
Java 的参数传递为 值传递. 也就是说, 当我们传递一个参数时, 方法内将获得实参的一个拷贝.
基本类型(int/char 等)的参数传递, 方法内获得是一个拷贝. Java 方法对变量的修改不会影响到原变量.
对象变量在 java 中实际是一个引用(可以理解为 C++的内存地址), 对象变量作为参数传递, 函数内获得一个引用地址的拷贝.
- 在函数内修改这个对象变量的值, 不会影响到函数外, 因为函数内修改的只是这个拷贝.
- 在函数内修改这个对象变量的成员, 会影响到函数外的对象
Swap
Java对普通类型的变量 or 引用类型的变量, 都无法简单通过=赋值实现 Swap,
折中的做法有: 1)使用数组, 2)作为成员变量
public static void swap1(int[] data, int a, int b) { |
变参函数
Java也支持变参函数:
void foo(String[] args) { //第一种形式 |
final 关键字
Java 中的 final 关键字和 C++中的 const 关键字一样, 都表示不可改变.
final 关键字可以修饰:
- 成员: 表示常量, 也可以在 final 成员定义时不给初值, 在构造方法里赋初值;
- 形参: 表示这个参数引用指向的内容不能被改变.
- 方法: 表示这个方法不能在派生类中被”覆写”(Override), 但可以被继承使用. 类中所有 private 方法都被隐式的声明为 final 的.
- 类: 表示这个类不能被继承, final 类中所有的方法也被隐式声明为 final 的, 设计类时候, 如果这个类不需要有子类, 类的实现细节不允许改变, 并且确信这个类不会载被扩展, 那么就设计为 final 类. final 和 abstract 这两个关键字是反相关的, final 类就不可能是 abstract 的
- C++的 const 类成员和 Java 的 final 类属性: 在 C/Java 的类中, 都支持
public final int ee = 1这样的声明+赋初值的方式, 也支持先声明再初值的方式(这种情况下, 都需要在构造函数里初值). 这样的设计的好处是可以做到一个类中 final 域在不同的对象有不同的值.
private final List Loans = new ArrayList(); |
下面总结了一些使用 final 关键字的好处:
- final 关键字提高了性能, JVM 和 Java 应用都会缓存 final 变量. @doubt
- final 变量可以安全的在多线程环境下进行共享, 而不需要额外的同步开销.
- 使用 final 关键字, JVM 会对方法/变量及类进行优化.
摘自《Java 编程思想》第四版第 143 页:
“使用 final 方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的 Java 实现版本中,会将 final 方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的 Java 版本中,不需要使用 final 方法进行这些优化了。“
static 关键字
使用 static 块初始化 final 的 Map:public class Test {
private static final Map<Integer, String> myMap;
static {
Map<Integer, String> aMap = ....;
aMap.put(1, "one");
aMap.put(2, "two");
myMap = Collections.unmodifiableMap(aMap);
}
}
回顾 C++的 const: 可以修饰函数(修饰返回值 or 修饰形参 or 修饰类的函数成员),
const int ptr; // ptr 指向的内容无法修改
int const ptr; // 指针 ptr 本身的值无法被修改
修饰形参: void func(const int *ptr);
修饰返回值: const &aaa func(void); //
修饰类的函数成员: void func(int, int) const; // 函数内不能修改类成员的值
面向对象
Object的一些默认方法
Object obj = new Object(); |
equals()
Object的equals方法默认是比较引用地址. equals方法的特点:
- 自反性: a.eq(a)==true
- 对称性: if a.eq(b)==true, then b.eq(a)==true
- 传递性: a->b, b->c, a->c
所以伪码如下:
if super.equals==false false |
hashCode()
hashCode()返回int类型, 返回值可以看成是对象的”消息摘要”
Object 默认的 hasCode()返回的并不是内存地址, hasCode()内部调用了 native 方法, 不同的 JVM 实现可能不一样, OpenJDK 的实现如下:
mark = monitor->header(); |
如果第一次hashCode, 则通过get_next_hash 重新获取一个随机值, 并保存在对象头
生成 hash 的最终函数 get_next_hash,这个函数提供了 6 种生成 hash 值的方法。
0. A randomly generated number. |
那么默认用哪一个呢?根据 globals.hpp,OpenJDK8默认采用第五种方法。而 OpenJDK7 和 OpenJDK6 都是使用第一种方法,即 随机数生成器。
@ref: java默认的hashcode方法到底得到的是什么? - 云+社区 - 腾讯云
equals() vs hashCode()
- 如果重新了equals方法, 就必须重写hashCode方法, 以便可以将对象插入到HashMap中(摘自Java核心技术卷1, 为什么?)
- 如果两个对象equals, 那么hashCode一定相同, 如果两个对象hashCode相同, 但不一定equals, 为什么?
- equals要依次比较每个属性的值, hashCode是对”需要比较的属性”求散列, 所以如果哈希方法不够好出现碰撞, hashCode相同但是每个属性不equals
- 因为HashMap插入时用Key的hashCode作为数组的下标, 所以hashCode返回必须是正int
- 好的hashCode方法应该对”需要比较的每个属性”充分散列
clone()
Object.clone默认是浅拷贝;
Cloneable接口
Cloneable和Serializable 一样都是标记型接口,它们内部都没有方法和属性,implements Cloneable表示该对象能被克隆,能使用Object.clone()方法。
如果没有implements Cloneable的类调用Object.clone()方法就会抛出 CloneNotSupportedException
Example:
public class Example implements Cloneable { |
Example类的 clone()默认调用了 Object.clone(), 这是一个Native方法, 默认是 浅克隆(shallow clone)
浅拷贝(浅克隆)复制出来的对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。
深拷贝(深克隆)复制出来的所有变量都含有与原来的对象相同的值,那些引用其他对象的变量将指向复制出来的新对象,而不再是原有的那些被引用的对象。换言之,深复制把要复制的对象所引用的对象都复制了一遍。
如何实现 deep clone:
clone方法里要对每个引用类型的成员都调用一次 clone(), 例子:
class Car implements Cloneable { |
使用Serializable实现深克隆(deep clone):
略
安全的类型转换
- 向上转型:
List<Object> list = new ArrayList<Object>(); - 向下转型:
ChildA child = (obj instanceof ChildA ? (ChildA)obj : null);
instanceof关键字用于判断一个引用类型变量所指向的对象是否是一个类(或接口、抽象类、父类)的实例。
构造和销毁
构造器(constructor):
Java的构造器实际上是一个static函数, 因为在没有实例化之前就可以调用构造, 但是一般来说, static方法里不能使用this关键字, 因为this的含义是指向类实例本身的一个引用(C++的this是指向类实例自身的指针), 但是构造器这个特殊的static方法里却可以使用this关键字.
继承和构造顺序
派生类被实例化时, 总是先调用super(), 即基类的默认构造方法. 在派生类的构造函数中, 也可以使用super(args...)调用指定的基类构造方法.
Class A { |
默认构造方法
如果一个类没有定义任何构造方法, 那么编译器会为这个类自动生成一个不带参数的默认构造方法,
销毁
- Java允许在类中定义一个
finalize()方法, 这个方法里可以做什么? JVM何时调用这个方法? - Efftive Java中提到
finalize()方法可用作”守卫方法”, 比如socket在这里做最后的关闭检查:
protect void finalize() { |
this关键字
- 在调用Java的方法时, 会隐式的将”指向自身的引用”作为方法的第一个参数
function(this, param), C++的this是”指向类实例自身”的指针; - static方法的第一个参数则是null.
访问控制权限
- 没有任何权限修饰, 默认是包内可见, friendly的;
- 访问权限 public > protected > friendly > private
- protected: 包可见, 子类可见;
- friendly: 包可见, 子类不可见 (没有这个关键字, 什么都不加默认是friendly);
- private: 只对该类型可见;
继承
多重继承
- Java不支持多重继承class, 但支持多重继承interface. 思考一个问题:
“有两个类B1和B2继承自A. 假设B1和B2都继承了A的方法并各自进行了覆盖, 编写了自己的实现. 假设C通过多重继承继承了B1和B2, 那么C应该同时继承B1和B2的重载方法, 那么它应该继承哪个的呢?是B1的还是B2的呢?”
C++中经常会掉入这个陷阱, 虽然它也提出了替代的方法来解决这个问题. 我们在Java中就不会出现这个问题. 就算两个接口拥有同样的方法, 实现的类只会有一个方法, 这个方法由实现的类编写. 动态的加载类会让多重继承的实现变得困难.
因为在C++没有Interface, 在C++中使用”虚拟继承”解决上面的问题:
- B1和B2去虚拟继承A:
class B1 : public virtual A,class B2 : public virtual A- C多重继承B1和B2:
class C : public B1, public B2;
抽象类和接口
- 含有抽象方法(abstract function)的类是抽象类(abstract class).
- 任何子类都必须实现抽象类的抽象方法, 或者自身也声明为抽象类;
抽象类public abstract class A, 和接口的异同:
- 抽象类和接口都能有自己的属性成员, 不同的是接口中的成员属性都是static和final的, 因此比较合适的做法是在interface里放置一些常量.
- 抽象类里还可以定义自己的方法实现, 并能被派生类继承, 但接口不能含有任何方法实现.
多态(polymorphism)
多态的含义就是一个方法多种实现, 分静态和动态, 在同一个类中实现多态是通过函数重载 -Overload, 在继承中实现多态是通过运行时绑定.
- 在Java的继承中, 除了static和final方法(private也是final的)之外, 其他的方法都是
运行时绑定的, - 类的属性成员并不在多态的讨论范围内, “多态”仅仅指方法的多态. 比如基类和派生类都有field属性, 那么在派生类实例中, 将包含两个field, 通过
基类.field也只能访问基类的field, 因为 属性没有多态. - 类的构造方法不具备多态性, 因为类的构造器默认是static属性的, 对比C++的构造也不具备多态性(C++通过虚函数实现), 原因是构造期间尚未生成虚函数表.
- 在派生类中, 覆写(Override)基类的私有方法不会编译报错, 但不会照期望的执行, 结论就是: 只有非private方法才可以被派生类覆写(Override).
Java 的运行时绑定,是通过 Klass 对象的 vtable 实现的 @ref: Advanced-Java.02b1.MetaSpace解析
Java 和 C++实现多态的对比
| C++ | Java |
|---|---|
| virtual func | 普通方法 |
| virtual f()=0 | abstract func() |
| abstract class | interface |
接口
@todo
内部类
一般内部类
- 外部类不一定有内部类实例, 但内部类一定有对应的外部类,
- 内部类的成员不能是static, 也不能有static代码块(但内部类可以是static的, 嵌套类)
- 外部类和内部类可以 互相访问 所有成员(包括private);
- 外部类可以访问内部类的一切成员, 无论这个内部类是 public 还是 private 的, 无论内部类的成员是 public 还是 private 的, 外部类通过
内部类实例.成员名访问内部类的成员; - 内部类可以访问外部类的一切成员, 包括外部类的 private 成员, 访问方式是
外部类类名.this.func(), 或者也可以”直接调用”外部类的成员.
- 外部类可以访问内部类的一切成员, 无论这个内部类是 public 还是 private 的, 无论内部类的成员是 public 还是 private 的, 外部类通过
- 在编译成功后, 会出现这样两个class文件:
Outer.class和Outer$Inner.class;
定义一个内部类:
public class Outter { |
外部类如何访问内部类
- 内部类访问外部类属性:
println(OutterClass.this.propertyName); - 外部类访问内部类属性:
println(inner.propertyName)// 必须先创建内部类实例inner - 在拥有外部类对象之前, 是不可能创建内部类对象的, 换句话说, 其他人只能通过外部类对象才能访问内部类:
Outter.Inner in = new Outter.Inner(); // ERROR! 要先创建外部类 |
其他类如何访问内部类
- public的内部类 的public成员是包可见;
- public的内部类 的private成员包不可见, 仅对外部类可见;
- 当Inner是private时, 其他类不能通过
Outter.Inner in = out.getInner()或者Outter.Inner in = out.new Inner的方式创建Inner对象, 因为Inner类就是private的;
但是, 如果private的Inner继承自一个Base类, 这个Base类又是包可见(Public)的, 那么可以通过Base base = out.getInner()的方式创建内部类对象, 换句话说, 这个Base是内部类的一个对外接口, 只能通过这个对外接口访问private的内部类;
以上参考: 探讨Java内部类的可见性; @ref
内部类的必要性?
- Java不允许多重继承, 使用内部类可以”继承”外部类的方法, 并且内部类可以独立的继承自另一个抽象类或者接口.
- 把实现细节放在内部类, 相当于是对外隐藏细节, 封装.
- 使用内部类最吸引人的原因是:每个内部类都能独立地继承一个(接口的)实现, 所以无论外围类是否已经继承了某个(接口的)实现, 对于内部类都没有影响[Think in Java]
局部内部类 & 匿名类
- 匿名类首先要有一个Interface or 基类;
- 匿名类没有名字, 也没有构造方法, 没有访问修饰符;
- 匿名类可以访问外部的变量, 但是创建匿名类的方法参数是final的;
定义一个匿名类:
/* 匿名类要有一个接口或基类 */ |
UI中大量使用的事件callback:
button.setOnClickListener(new OnClickListener() { |
嵌套内部类
- static的内部类被称为嵌套类, 嵌套内部类不需要由外部类创建, 也就没有隐藏的外部类引用
- 不能调用非 static 的外部类成员, 即不能访问
Outter.this.property; - 外部类初始化的时候, 不会触发嵌套内部类的初始化.
静态内部类的初始化的时机:
初始化时会初始化 static 成员变量, 执行 static 代码块, JVM 会把这些操作放在一个叫clint的方法中执行
字符串
- String是一个特殊的类, 不需要构造函数就可以创建实例
String s = "hello world"; - String的
char[]是final static的, 只有一份拷贝.一旦String被创建, 字符串的内容就不可改变了 // Question: 当new一个String时, 是如何判断字符串池里是否已经有相同字符串的? - 字符串的比较不能使用
==:==仍然比较的是引用, 而应该使用String.equals()
String一些方法和实现
bool contains(String str): 判断参数s是否被包含在字符串中,并返回一个布尔类型的值int indexOf(String str, int fromIndex):String substring(int beginIndex, int endIndex): 该方法从beginIndex位置起,从当前字符串中取出到endIndex-1位置的字符作为一个新的字符串返回。int compareTo(String anotherString): 该方法是对字符串内容按字典顺序进行大小比较,通过返回的整数值指明当前字符串与参数字符串的大小关系。若当前对象比参数大则返回正整数,反之返回负整数,相等返回0。boolean equals(Object anotherObject): 比较当前字符串和参数字符串,在两个字符串相等的时候返回true,否则返回false。- 比较引用是否相等
- 要比较的对象是否
instanceof String - 比较数组的长度 & 依次比较每个char
String concat(String str): 将参数中的字符串str连接到当前字符串的后面, 生成一个新字符串返回String replace(char oldChar, char newChar): 用字符newChar替换当前字符串中所有的oldChar字符,并返回一个新的字符串。String replaceAll(String regex, String replacement): 该方法用字符replacement的内容替换当前字符串中遇到的所有和字符串regex相匹配的子串,应将新的字符串返回。
String 不可被继承
public final class String implements java.io.Serializable, Comparable<String>, CharSequence |
比较StringBuffer
- StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。两者的
char []不是final的, 可以修改; - StringBuffer线程安全, 所有方法都是synchronized的;
/* 比较 `String concat(String)`, `+`, 以及 StringBuffer 效率*/ |
String,char,byte的互转
- String是由
char[]存储数据, char是unicode, 用16bit(2字节)的数值表示一个char:char c = '\u554a'; - String和char都可以用
\u0000这种方式初始化. - byte是字节, String/char转为byte[]时, 不能确定byte[]的长度, 视转换用哪种编码(GBK/UTF-8)而定.
String string = "\u0048\u0069"; // Unicode对应的字符串是"Hi" |
String str = "嘿H1"; |
unicode编码只指定了编码值, gbk和utf8定义了如何存储编码值.
- 一个char存储的是16位的unicode, 范围0~0xFFFF(65535), 超过这个范围的汉字, 比如”𩄀”, 要用两个char也就是4字节表示.
- 如果unicode用gbk编码, 一个中文3字节, 一个英文1字节;
- 如果unicode用utf-8编码, 中文2字节, 英文一字节;
- 所以上面的输出分别是3, 5, 6, 3;
常用类
String & StringBuffer
见 字符串
包装类
见 数据类型
Math类
@todo
日期类
- SimpleDateFormat 不是线程安全的
- JDK8 的 DateTimeFormatter 线程安全
使用 DateTimeFormatter 替换 SimpleDateFormat: 你真的会使用SimpleDateFormat吗? - 知乎
异常处理
图-Java异常类的层次结构: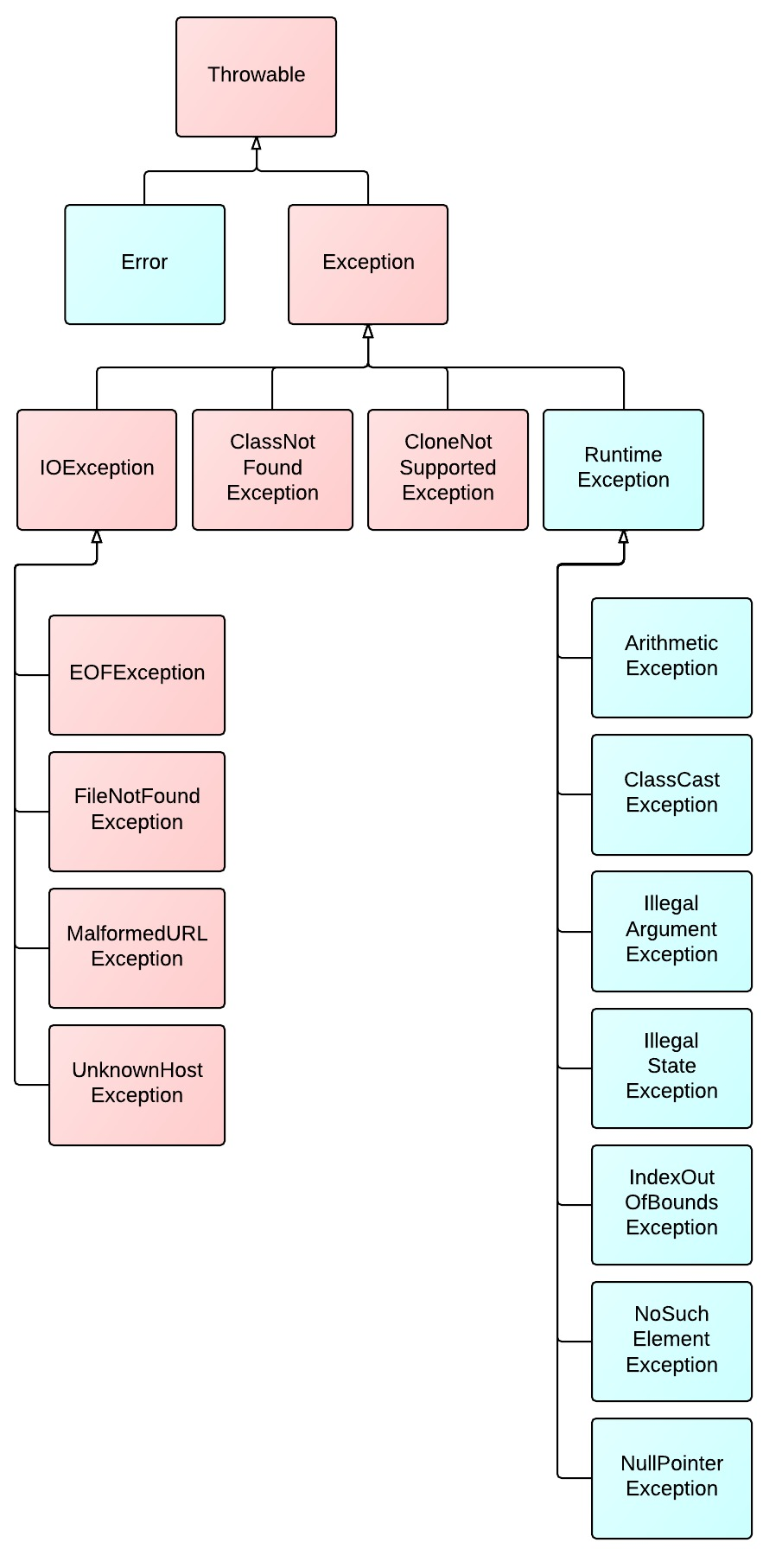
Error & Exception
在 Java 语言规范中,所有异常都是 Throwable 类或者其子类的实例。Throwable 有两大直接子类。第一个是 Error,涵盖程序不应捕获的异常。当程序触发 Error 时,它的执行状态已经无法恢复,需要中止线程甚至是中止虚拟机。第二子类则是 Exception,涵盖程序可能需要捕获并且处理的异常。
- Error 是程序无法处理的, 内存不足或JVM的错误, 比如
OutOfMemoryError,ThreadDeath - Exception 可由程序处理, 又分为”CheckedException”(受捡异常, 上图粉红色), 和”UncheckedException”(不受检异常, 上图蓝色)
- 前者是程序需要捕获并处理的异常(比如打开文件错误, 网络超时等待), 需要throws-try-catch语句显式的捕获;
- 后者是代码错误, 比如数组越界, 这种不需要明确throws, 如果throws了也不强制代码必须catch, 其实Error也能算是不受检异常;
继承关系
Throwable |
try-catch
如果该异常被 catch 代码块捕获,finally 代码块则在 catch 代码块之后运行。
在某些不幸的情况下,catch 代码块也触发了异常,那么 finally 代码块同样会运行,并会抛出 catch 代码块触发的异常。
在某些极端不幸的情况下,finally 代码块也触发了异常,那么只好中断当前 finally 代码块的执行,并往外抛异常。
try-catch-finally中的 return
// x返回多少? 会打印出什么? |
结果:返回 2
如果在 try-catch-finally 3个位置分别插入 return ,代码会如何执行?
需要先明白一些概念:
- 每个 java 方法执行时都会创建一个栈帧,栈帧中比较重要的数据结构有:操作数栈、局部变量表
- 局部变量表:可以认为是一个数组,里面存储了方法内出现的所有局部变量
- 操作数栈:存放的是运行时的指令,也是栈结构,运行的指令依次进栈,运行完后 pop
- 编译过程中,如果一个方法里有 finally,为了保证它一定被执行,会在任何可能的代码执行路径的出口处,增加一段 finally 代码块,例如 try 的出口处增加 finally 块,catch 的出口处增加 finally 块.. 如果不知道这一点,那么看字节码会有疑惑,为什么会出现很多重复的字节码?
扩展阅读:
- 06 | JVM是如何处理异常的?
- JVM 运行时数据区: 局部变量表 & 操作数栈 https://developer.aliyun.com/article/825859
如果 try 语句里有 return,那么代码的行为如下(见《Java Virtual Machine Specification》的 Chapter 4. The class File Format 中,「 Exceptions and finally」):
If the try clause executes a return, the compiled code does the following:
- Saves the return value (if any) in a local variable.
- Executes a jsr to the code for the finally clause.
- Upon return from the finally clause, returns the value saved in the local variable.
意思是:
如果 try 语句里有 return,那么代码的行为如下:
1.如果有返回值,就把返回值保存到局部变量中
2.执行jsr指令跳到finally语句里执行
3.执行完finally语句后,返回之前保存在局部变量表里的值
那么字节码是如何实现上面的标准描述呢?
- 为了保证 finally 一定被执行,所以会在 try 块的出口处,也增加 finally 代码块字节码
- 字节码对于返回值的处理是这样的,如果要把 a 这个局部变量作为返回值,那么
return a这个 java 代码,翻译为字节码是:iload_1然后ireturn, 解释,把局部变量 a 加载到操作数栈,然后调用 ireturn 返回之。这里的 iload_1是返回局部变量表中1的位置(假定变量 a 在局部变量表位置1) - 明白了对于返回值的处理,再看字节码就会清楚一些:
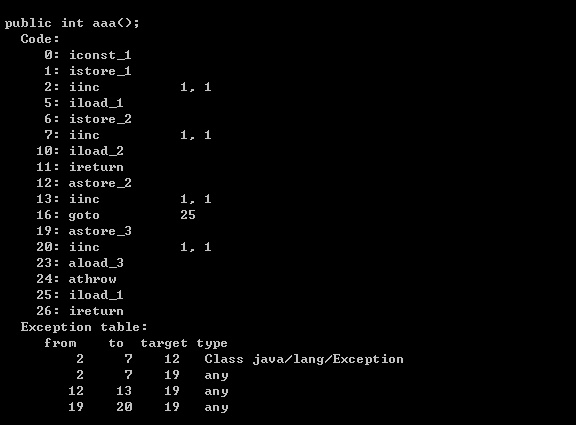
- 0-2,是 try 中的++
- 5-6是 finally 的++,注意这里++完,
istore_2把 x 保存在了本地变量表2的位置 - 10-11 是 return 之前
iload_2是将本地变量表位置2的数据,放入操作数栈,然后ireturn返回
getMessage vs toString

如代码所示,e.toString() 获取的信息包括异常类型和异常详细消息,而e.getMessage()只是获取了异常的详细消息字符串,
所以推荐在Catch中使用e.toString()
常见异常及解释
断言
- 表达式
assert 表达式:错误消息比如assert x>y : "断言失败!" - 如何开启关闭断言? 单点为某个类开启断言?
java -ea Xxx,java -ea:MyClass Xxx
Native Method
实现一个Native方法:
声明java native method:
public class CJNativeInterfaceDemo {
public native String input(String prompt);
static {
System.loadLibrary("./libJniTest.so");
}
public static void main(String[] args) {
CJNativeInterfaceDemo jniDemo = new CJNativeInterfaceDemo();
jniDemo.input("JNI Test");
}
}生成c++头文件
javac CJNativeInterfaceDemo.java生成.class文件javah -jni CJNativeInterfaceDemo生成.h文件
实现C++函数并编译成动态库
gcc -I/usr/lib/jvm/java-7-openjdk-i386/include/ CJNativeInterfaceDemo.c -shared -o libJniTest.so
附录:JDK常用类
java.lang📦继承关系图
java.util📦继承关系图
附录:补码,反码
反码: 正数的反码是本身, 负数的反码=符号位不变, 其他位取反
补码: 正数的补码是本身, 负数的补码=符号位不变, 其他位取反, 再加1
看几组补码-真值: “1111 1111”=-1, “1000 0010”=-126, “1000 001”=-127, “1000 0000”=-128
不要用计算补码的方式去”算”-128的补码, 1000 0000 是定义的.
参考:
- @ref 原码, 反码, 补码 详解
- @ref 原码、反码和补码
取余 & 取模
- 取余:
x%y - 取模:
Math.floorMod(x, y)
取余和取模的区别 =》 [[../19.Algorithm/Alg.数学基础]] 的「取余 & 取模」
位运算符
&符号位|符号位~符号位^符号位<<左移: 丢弃最高位(符号位同样丢弃), 0补最低位. 当byte和short左移时, 自动升级为int型.- 数学意义: 左移n位相等于乘以2^n
>>右移: 高位补充符号位, 正数右移补充0, 负数右移补充1, 当byte和short右移时, 自动升级为int型.- 数学意义: 右移n位相当于除以2^n
>>>无符号右移: 无论正负, 高位补充0- 无符号右移运算符>>> 只是对32位和64位的值有意义