JDK6 时期
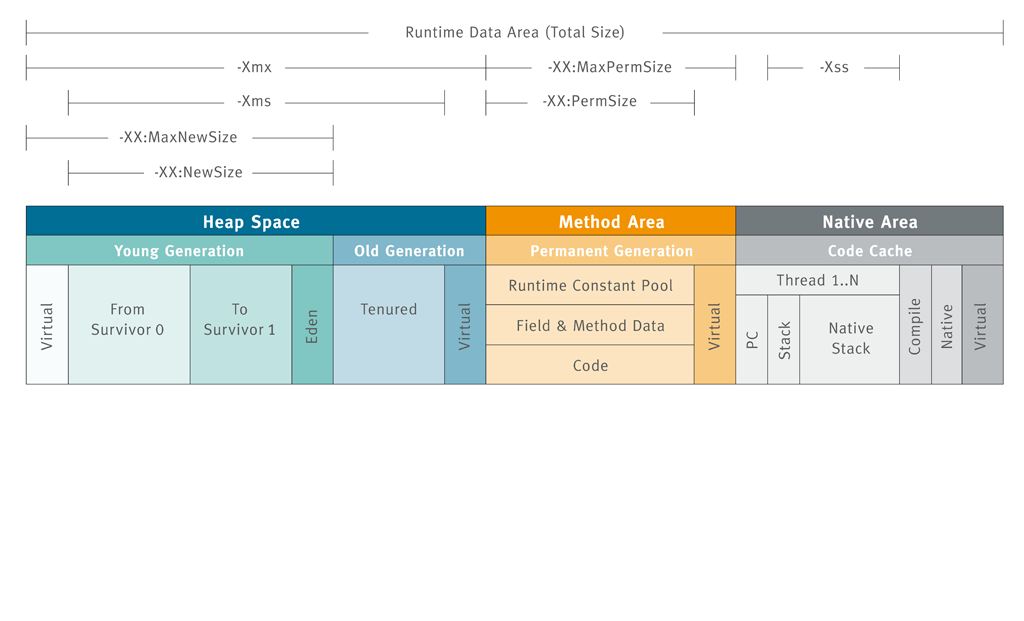
如上图, JDK6 时代的 JVM 内存分为下面几个部分:
- 堆区(Heap Space): 这部分被所有线程共享(除了 #TLAB ), 包括:
- 年轻代:
eden:s0:s1的默认比例是8:1:1, 可见 eden 区大部分对象都是要被回收的; - 老年代:
老年代:年轻代的比例默认是2:1, 也就是说默认情况下堆区的 2/3 都属于老年代,
- 年轻代:
- 栈区(Stack Space): 每个线程独有, 包括: PC, Stack, Native Stack
- 方法区(Method Area)
JVM 标准定义的内存区域为 Heap/Stack Space/Medhod Area; 分代的名称(年轻代/老年代/永久代)是 HotSpot 中定义的, 并不是 JVM 标准中定义的, 注意区分 @doubt
Heap
- 这块区域被同一 JVM 实例的所有线程共享(除了 TLAB), new 在堆创建对象.
- 堆的大小由
-Xms~-Xmx指定:-Xmx2048m -Xms2048m-Xmx堆的最大值默认是内存的 1/4;-Xms堆的最小值;
YoungGen(新生代)
大小由参数 -XX:NewSize ~ -XX:MaxNewSize (jdk 1.3)指定, jdk1.4之后统一成一个参数 -Xmn512m
新生代又被分为三个区域:
- Eden: 新创建的对象被分配在这里;
- To Survivor、From Survivor: 发生 Young GC 时, 有用的对象从
Eden区域和From Survivor区域移动到 →To Survivor, Eden 和 From 被清空, 同时 From 和 To 交换角色 ;
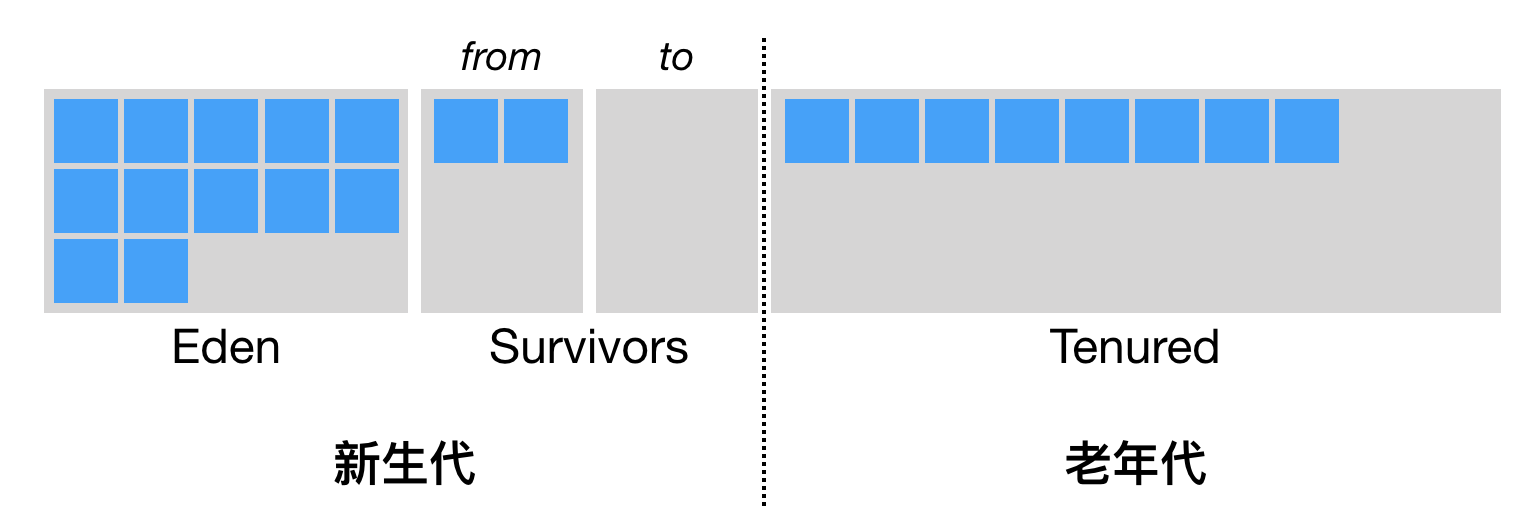
命令 jstat 的返回中, To/From Survivor 被标注为 S0/S1
Eden 区的 TLAB
在Eden区,每个线程都有一块自己的TLAB(Thread Local Allocate Buffer),线程创建的对象优先在自己的TLAB中分配,其他的线程仍可以访问这些对象,但是无法在其他线程的TLAB中分配内存。
为什么需要为每个线程单独分配TLAB?
- 内存分配要涉及到“空闲内存管理”,即把空闲的内存块管理起来,分配内存时从空闲块中取,一般的连续空闲内存管理使用:指针碰撞+空闲列表
- bump-the-pointer:在连续的内存块上,指针之前表示已用区域,指针之后表示未用,分配内存时移动指针即可,但是对于前面已分配过的内存,可能因为释放导致空洞,指针碰撞法无法管理这部分空洞
- free-list:对于指针碰撞法的补充,指针前面出现的空洞,用链表管理起来
- 实际分配时,在free-list 和 撞针寻找空闲的内存,这里通常使用 first-fit的方式寻找
- 多个进程都需要申请内存,就需要对 pointer & free-list进行加锁,导致性能下降
【图】使用 list 管理不连续的空闲块:
@link:: pointer & free-list 的空闲管理,比较物理内存的伙伴系统 & Slab内存池
其实“bump-the-pointer”翻译为指针加法更合适,而不是“指针碰撞”
我猜测会有留言问为什么不把 bump the pointer 翻译成指针碰撞。这里先解释一下,在英语中我们通常省略了 bump up the pointer 中的 up。在这个上下文中 bump 的含义应为“提高”。另外一个例子是当我们发布软件的新版本时,也会说 bump the version number。
线程向 TLAB 申请内存也是用““bump-the-pointer”:线程维护了两个指针(实际可能更多,但重要的就2个指针),end-ptr 指向 TLAB 末尾,free-ptr 指向“已分配”的后面,线程向 TLAB 申请内存只需向后移动 free-ptr
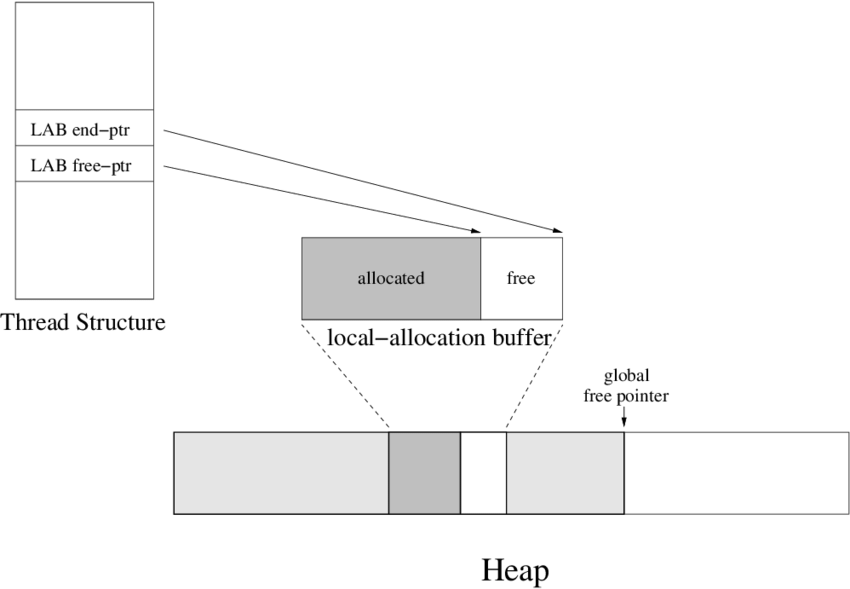
TLAB的创建、释放:
- TLAB在 线程初始化时创建,在经历一次GC后会释放TLAB,在GC过程中TLAB中的可达对象被放入Survivor Space,TLAB的内存区域也被释放给Eden 管理;
- 在GC完之后,线程尝试分配对象时,再次创建新的TLAB;
- 如果一次 new 的内存块的大小,大于当前 TLAB 剩余空间,此时还需要判断剩余空间是否大于refill_waste(最大可浪费):
- 如果TLAB的剩余容量,大于 refill_waste:在堆内存分配
- 如果TLAB的剩余容量,小于 refill_waste:TLAB 被退回给 Eden,线程不再使用这块 TLAB 分配,而是申请新的 TLAB
- 通过 refill_waste,减少重新申请 TLAB 的频次
TLAB参数:
-XX:-ResizeTLAB: 关闭 TLAB的 resize,默认是开的,会根据线程分配历史动态调整TLAB的大小-XX:TLABRefillWasteFraction=64最大可浪费 TLAB的 1/64
@ref:
OldGen(老年代)
- 也叫 Tenured(晋升代), 在 GC 里被称为老年代(Old Generation)
- 没有参数可以指定大小, 但可以通过
Heap-新生代计算出来
Stack
当每个新线程出现时,都会获得自己的 PC Register、Java Stack、以及 Native Method Stack
(1)Program Counter Register:
计数器, 记录当前线程执行 Java 字节码的行号;
这里是 JVM 中唯一没有规定任何 OutOfMemoryError 的区域;
(2)Java Stack:
即每个线程执行时的 “Java 栈”,区别于 Native, 每个线程的栈由一个个栈帧(Frame)构成,线程中每次有方法调用时,会创建一个 Frame 并压入 Java Stack,方法调用结束时 Frame 被弹出,Java 的方法结束有两种方式:
- return
抛出异常
该区域存储线程的 Java 方法(再次强调不包括 Native method 的)调用的状态,包括其局部变量、调用它的参数、返回值和中间计算。
该区域会抛出 StackOverflowError 和 OutOfMemoryError
(3)Native Method Stack:
除了上面的栈, 每个线程都有自己的 Native 方法执行栈, Java Stack 是线程执行字节码的栈, Native Stack 是线程执行 Native 代码的栈) ;
该区域会抛出 StackOverflowError 和 OutOfMemoryError;
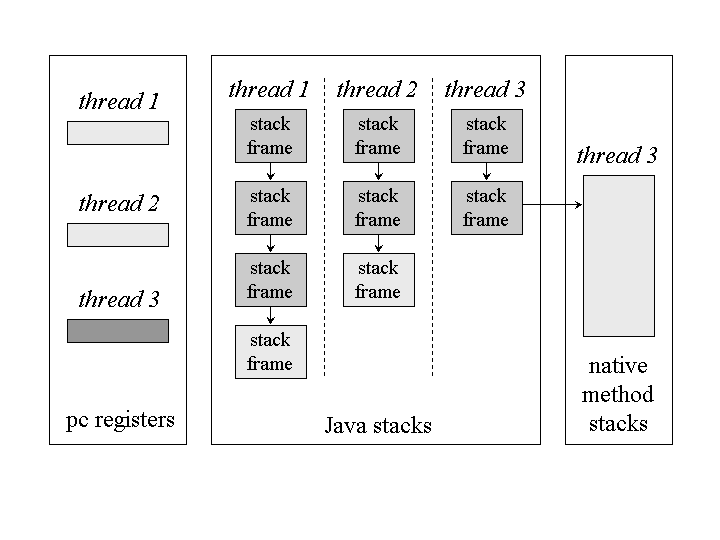
上图显示了正在执行三个线程的虚拟机实例的快照:线程 1 和 2 正在执行 Java Method。线程三是执行 Native Method。
Stack 显示为向下增长。每个线程的 Java Stack 的“栈顶”显示在图的底部。
对于当前正在执行 Java Method 的线程,pc 寄存器指示要执行的下一条指令。
由于线程 3 当前正在执行 Native Method,因此其 pc 寄存器(以深灰色显示的内容)的内容未定义。
线程栈大小由参数
-Xss指定, 默认 1m, 在 tomcat 这种多线程 web 服务器上, 保持 1m 或者更小可以处理更多的并发请求
Stack 和 Native Stack 都会抛出 StackOverFlowError 和 OutOfMemoryError 两种错误,StackOverFlowError: 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 异常。
OutOfMemoryError: 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出 OutOfMemoryError 异常。
Method Area
方法区与堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
在 HotSpot 虚拟机中方法区也常被称为 “永久代”。也仅仅是 HotSpot VM 这么做,对于其他的虚拟机(如 Oracle JRockit、IBM J9 等)来说是不存在永久代的概念的。HotSpot 虚拟机设计团队用“永久代”来实现方法区而已,这样 HotSpot 虚拟机的垃圾收集器就可以像管理 Heap 一样管理这部分内存,能够省去专门为方法区编写内存管理代码的工作。
在 HotSpot VM, 永久代也是有 GC 的, 时机与老年代相同(再次提醒 永久代不属于堆)
HotSpot VM 的永久代大小由
-XX:PermSize~-XX:MaxPermSize指定, 一般服务器设置为:-XX:MaxPermSize=500m
JDK 1.6 时期,HotSpot 的永久代包括:
- Runtime Constant Pool, 运行时常量池
- String Pool: 字符串常量池, 以”Hello”字面量方式创建的字符串会存储在这里. 详见 「字符串在内存中的存储」
如果运行时有大量的类产生,可能会导致方法区被填满直至溢出。报出 java.lang.OutOfMemoryError: PermGen space,常见的应用场景如:
- Spring 和 ORM 框架使用 CGLib 操纵字节码对类进行增强,增强的类越多,就需要越大的方法区来保证动态生成的 Class 可以加载入内存。
- 大量 JSP 或动态产生 JSP 文件的应用(JSP 第一次运行时需要编译为 Java 类)。
- 基于 OSGi 的应用(即使是同一个类文件,被不同的类加载器加载也会视为不同的类)。
JDK7 时期
String Pool (字符串常量池)被从 PermGen 里移除了, 这部分字符串对象放在了 Heap 里, 并且可以通过 -XX:StringTableSize 指定其大小,这部分的变化参考 [[#字符串在内存中的存储]]
此外 JDK7 的内存模型基本和 6 一样;
•JDK6~7 的 VM 参数总结
<JVM 6 & 7 Memory options> |
JDK8 时期(MetaSpace)
在 HotSpot JDK7以及更早的版本里, 永久代最大大小由 -XX:MaxPermSize 指定, 一旦超过这个大小就不能再扩展, 假如加载的类过多会导致 Medhod Area 过大而导致 OOM,
HotSpot JDK8 移除 了 JDK7 的 PermGen(永久代), 类的元信息被移到了 MetaSpace(元空间), 这块内存放在 Native memory 当中, 不再属于 JVM 线程内的内存区.
interned 的 String、类的 static 成员在堆区 jvm - Where are static methods and static variables stored in Java? - Stack Overflow
JDK7 移除了 PermGen 的「字符串常量池」;
JDK8 移除了整个 PermGen, 类的元信息被放在 MateSpace;
更多关于 MetaSpace -> Advanced-Java.02b1.MetaSpace解析
JVM 分代设置大小建议
- 堆区的默认值最大 size 是256MB, 永久代默认最大 size 是64MB,
堆:永久代大约是是4:1(Test @ JDK6 + Windows 32 bit) - 每个分代大小比例(经验值):
Eden : Survivor0 : Survivor1 : OldGen : PermGen = 8 : 1 : 1 : 20 : 5 - 每个分代具体设置多大, 还可以根据 JVM 活跃数据 的大小进行估算:
活跃数据的大小是指,应用程序稳定运行时长期存活对象在堆中占用的空间大小,也就是 Full GC 后堆中老年代占用空间的大小。可以通过 GC 日志中 Full GC 之后老年代数据大小得出,比较准确的方法是在程序稳定后,多次获取 GC 数据,通过取平均值的方式计算活跃数据的大小。活跃数据和各分区之间的比例关系如下

例如,根据 GC 日志获得老年代的活跃数据大小为 300M,那么各分区大小可以设为:
总堆:1200MB = 300MB × 4 |
变量在JVM内存中的存储
不同方式创建的变量 & 常量,在 JVM 存储的位置:
Stack(栈区):
- 局部变量,保存在每个方法的栈帧中的“局部变量表”中
- 如果局部变量是类引用,引用本身也在局部变量表,引用指向的 object 在Heap
Heap(堆区):
- 每个 Object 对应的 Class Object
- Object 的普通成员变量(除 static、final 之外的)
- Object 的 static 成员:在堆
- Object 的 final 成员:
- 基本类型的 final(int、double):在 Metaspace 的常量池
- 引用类型的 final:
- 字符串常量(字面量): 字符串常量池在 JDK7 之后移到了堆区
JVM Storage for Static Members | Baeldung:
Before Java 8, PermGen stores static members like static methods and static variables. Additionally, PermGen also stores interned strings.
As we’ve already discussed, PermGen space is replaced with Metaspace in Java 8, resulting in a change for memory allocation of the static members.
Since Java 8, Metaspace only stores the class metadata, and heap memory keeps the static members. Furthermore, the heap memory also provides storage for interned strings.
MateSpace:
这部分存储的内容参考 Advanced-Java.02b1.MetaSpace解析
对象在内存中的结构 @ref Advanced-Java.05.对象内存结构
字符串在JVM内存中的存储
1.6之前的不管了,只看1.7及之后的:
- 双引号创建的
String s = "hello",存储在堆中,但是”hello”会被放入 Sring Pool String s = new String("hello")涉及到两个 string 对象:构造方法创建的存储在 Heap,另一个双引号创建的在 String Pool;
String Pool 与 String.intern()
Java 并不要求常量只在编译期产生, 并非只有 class 文件常量池的内容才能进入方法区的”运行时常量池”,;
运行期间可以添加常量进入常量池, 比如 String.intern() 方法
intern() 的作用是将该字符串驻留在 String Pool 中,如果 String Pool 中已存在当前字符串,就会直接返回当前字符串引用. 如果常量池中没有此字符串, 会将此字符串放入 Pool 中后再返回;
但要注意:
- String Pool 中保存的是地址, 指向 Heap 中的 String 对象;
- String Pool 是 C++实现的 HashTable,也就是 HashTable 对象是在 vm 的 Native 内存,而不是在 Heap,但指向的 String 在 Heap;
- JDK7之后的 String Pool 是一个固定大小的 HashTable(通过 vm 参数
-XX:StringTableSize指定大小,默认1009),因为 HashTable 大小固定,一旦 intern 的字符串数量过多,会导致链表过长,intern 性能下降, - 这时 HashTable 也会 rehash,但不会扩容,而是重新生成 hash 的 seed 减少碰撞。但因为没有扩容,所以对于非常满的 HashTable,rehash 后效果不大;
JDK7之后 String Pool 的实现在 \openjdk7\hotspot\src\share\vm\classfile\symbolTable.cpp :
oop StringTable::intern(Handle string_or_null, jchar* name, int len, TRAPS) { |
主要做的是 lookup 和 basic_add ,如果 hashTable 冲突严重导致链表过长,lookup 耗时也会增加;
➤ intern 使用场景:
- 如果产生很多相同的字符串,intern 可以减少 string 对象的内存占用,但响应的增加了 intern 的耗时——主要是在 HashTable 的查找上
对于大量但重复的字符串,可以使用 intern 放入 String pool,并使用 intern 获取 :
String symbol = new String(character).intern();
除了 Java 代码中可以调用,VM 的 C++代码也可以调用 intern 向 String Pool 中插入数据,例如
Thread.currentThread().getStackTrace(),获取类名和方法名是通过 intern 获取:oop classname = StringTable::intern((char*) str, CHECK_0);
oop methodname = StringTable::intern(method->name(), CHECK_0);
oop filename = StringTable::intern(source, CHECK_0);
➤ intern 使用建议:
- 如果创建的重复字符串很多,intern 可以减少内存使用
- String Pool 大小由 vm 参数指定,不可动态修改,也不会扩容,是根据自身需要调整
StringTableSize,代码中使用 intern 的要能确认所需 String pool 的容量范围
➤ GC 和 intern 的问题:
- YGC 时需要扫描 String Pool,防止其中的在 YoungGen 分配的 string 对象被回收
- @doubt:在 String Pool 中的 string 如果晋升 or 内存地址发生变化,需要同步修改 String Pool?
- @doubt: oldGC 是不是也需要扫描 String Pool?
- 既然 YGC 是需要扫描 String Pool 的,那么过于庞大的 String Pool 也会影响 YGC 时间
@ref:
JDK6,7,8 的 String Pool
- JDK6: GermGen 的大小在64位机器上一般为96MB, 由
-XX:MaxPermSize指定, String Pool(主要是个 C++描述的 StringTable)的大小默认是 1009(StringTable “桶”的大小), 且这个大小不能扩展, StringTable 的实现原理类似 HashMap, hash 值相同的会放进同一个桶的链表里. 如果太多调用了String.intern(), 会导致这个 StringTable 性能下降. - JDK7: String Pool 从 PermGen 移到 Heap, 并且增加了
-XX:StringTableSize参数可以配置 String Pool 的大小,-XX:StringTableSize=1000003. - JDK8: String Pool 与7相比没有太大变化,
-XX:StringTableSize默认是 60013, 可以用-XX:+PrintFlagsFinal 获取当前你使用的值是多少.
以上参考自:String.intern in Java 6, 7 and 8 - string pooling - Java Performance Tuning Guide @ref
下面代码运行结果是 ?
String s = new String("1"); // 两个对象, 字面量"1" & new 创建的str |
先说答案: 在 JDK6 下结果是 “false false”, 在 JDK8 下是 “false, true”.
没有在 JDK8 上验证, 但我觉得 7 和 8 在 String Pool 上改动不大, 8 仅仅是把 Method Area 移动到了 Native Memory 中 –被叫做 Metespace(元空间)的区域.
因为看不到 HotSpot 的 native 层源码, 所以只能看 OpenJDK 的, 但是不保证 OpenJDK 与 HotSpot 实现一样 @todo 有时间一定要看了才能解惑.
public String intern()
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the class String.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
从 JDK6 到 JDK7 的 String Pool 和 intern 方法的改变都比较大(String Pool 从 PermGen 移动到了 Heap, String.intern() 改变见下面的分析)
in JDK6:
String s = new String("Hello")会创建两个字符串对象, 一个在 String Pool 里的字面值, 一个是 Heap 里的对象.intern()方法首先在 String Pool 里查找是否有 equals 的字符串, 如果没有则在 String Pool 创建一个字面量字符串, 并返回其引用. 已经存在的话返回在 String Pool 里的引用.
String s = new String("1"), s 创建后, String Pool 和 Heap 各创建一个”1”, s 指向的是 Heap 里的对象;String s2 = "1", s2 指向的是 String Pool 里的字面值;String s3 = new String("1") + new String("1")这时”11”在内存里只有 Heap 里的一个, s3 指向这个 Heap 里的对象,s3.intern之后 String Pool 里也创建一个”11”;String s4 = "11"s4 指向的是 String Pool 里的对象
in JDK7:
String s = new String("Hello")的行为跟 6 一样;str.intern()执行后, 如果再 String Pool 里没有到 equals 的字符串, 就不再在 String Pool 里创建对象了, 而是直接把 Heap 里的对象引用放进来. // 这也是 6->7 的 String 的一个重要改变, 减少重复的字符串创建, 也更节省内存.
String s = new String("1"), s 创建后, String Pool 和 Heap 各创建一个”1”, s 指向的是 Heap 里的对象;s.intern()检查 String Pool 里已经存在”1”的字面值了, 什么都不做;String s2 = "1", s2 指向的是 String Pool 里的字面值, 故s == s2输出 false;String s3 = new String("1") + new String("1")这时”11”在内存里只有 Heap 里的一个, s3 指向这个 Heap 里的对象,s3.intern()在 String Pool 里找不到”11”, 但是不再创建新的, 而是直接把 s3 的引用复制进 String Pool,String s4 = "11"这种方式创建是指明在 String Pool 里创建, 但是 String Pool 里已经存在一个”11”的引用了, 那么 s4 直接指向这个引用. 所以 s3 和 s4 指向的都是 Heap 里的”11”, 故s3== s4输出 true;
•内存分区可能抛出的错误
- Stack :
StackOverflowError&OutOfMemoryError - Heap:
OutOfMemoryError - Method:
OutOfMemoryError: PermGen space(1.8 之前) - MetaSpace:
OutOfMemoryError: Metaspace(1.8+):