Golang中的约定大于配置
Golang遵循”约定大于配置”(convention over configuratio)的理念:
- 小写开头的标识(变量/函数/结构体类型等等)是 package 内可见, 大写开头的标识包外可见(类似 public)
结构体中的”小写开头的成员”, 在用
json.Marshal序列化时会被忽略每个文件是一个 package,声明在源文件第一行,
package main是一个特殊的包import as
_和.的包:import . "packageXXX": 调用包内的函数,不需要再加packageXXX.import _ "packageXXX": 匿名导入,并不使用包内导出的函数,而是仅仅让包的 init 得到调用
单元测试:
- 文件名:
源文件名_test.go - 函数名:
func Test源函数名()
- 文件名:
Package & Import
// A package clause starts every source file. |
init
init()函数特性:
- 在 main 之前, 由 runtime 调用
- 同一个 go 文件下, 可以有多个 init 函数, 调用顺序同定义顺序
- 同一个 package 下, 可以有多个 init 函数, 调用顺序似乎是 go 文件字典顺序, 但不要依赖此顺序做初始化
- 对于 import 导入的包,这些导入的包的 init 的调用顺序同 import 的顺序
- 用户代码无法调用
init(), 会报错 undefined
➤ init 使用场景:
- 做初始化;
- 实现 sync.Once 功能;
- 无法用初始化表达式初始的变量;
变量
变量的声明 + 初始化:
var i int = 1
// 更方便的写法
j := 1
全局变量
Go 支持全局变量,首字母大写的变量名表示可被外界访问:
package mypkg |
基本数据类型
整形:
uint8/int8: 平台无关, 8位uint16/int16: ..uint32/int32: ..uint64/int64: ..uint/int: 平台有关,可能是32 or 64 bits(视机器平台而定)
浮点数:
float32:平台无关,4位float64:…
复数:
complex64: 复数, 由float32的实部 + float32的虚部构成
@ref: The Go Programming Language Specification - The Go Programming Language
string
双引号和反引号:
str1 := "string example"
str2 := `another string
example`
str3 := `{"type": "json"}`字符串是”只读的”, 意味着无法直接修改字符串的内存空间
字符串的实现,运行时使用
reflect.StringHeader结构体表示字符串,与切片的结构体(SliceHeader)相比,字符串只少了一个表示容量的Cap字段:type StringHeader struct {
Data uintptr
Len int
}判断字符串 empty:
len(str) == 0
类型转换
Golang的类型转换:
T(var)字符串 → any 都可以用
strconv:i, err := strconv.ParseInt("1287089", 10, 32)
result := int(i)
函数
Golang 函数声明的不同之处:形参列表后面才是返回值,返回值可以有多个,变量名在前类型在后
多个返回值:
// 多个返回
func foo1(x, y int) (sum, prod int) {
return x+y, x*y
}可变参数:
// 可变参数
func foo1(params ...type) {
for _, param := range params {
...
}
}Golang 是值传递还是引用传递?
- Golang 是值传递, 函数内得到一份形参的拷贝
- 对于 slice, map, chan, 因为其结构内包含指针, 所以仍可以在函数内改变其存储的值
- 数组也是值传递,因为数组的类型是
[N]Type,所以数组作为形参是有局限性的,大小 N 被固定,推荐用 slice
闭包(closure)
例1:
x := 1 |
例2:
func foo2(x int) func() { |
- 什么是闭包(closure)? a closure is a record storing a function together with an environment., 那么闭包的简化定义是: 函数+依赖的外部变量(不以参数传入的变量)
- 实际上, Golang 实现闭包, 实际是把 函数 和它依赖的外部变量 都放在了一个 struct 里, 用这个 struct 保存了函数地址,和它依赖的外部变量(的引用)
- 闭包的实现依赖 Golang 的逃逸分析, 在逃逸分析时,闭包依赖的外部环境变量,被判定为逃逸,则在堆上分配;
- 闭包另一个特性是延迟绑定, 意思是, 上面的闭包(也即 struct)里保存的环境变量的值, 不是在编译期确定的, 而是在闭包的运行时才确定, 在闭包的外部寻找依赖变量的最新值, 并赋值进去 // 闭包的运行时即
闭包()时;
闭包 - 维基百科,自由的百科全书)
在支持头等函数的语言中,如果函数f内定义了函数g,那么如果g存在自由变量,且这些自由变量没有在编译过程中被优化掉,那么将产生闭包。
再使用一个例子说明闭包的延迟绑定,下面输出什么?
func foo(x int) []func() { |
这类问题的通解是:
- 找出闭包,找出闭包依赖的外部变量
- 在闭包运行时(调用
func()时),找到外部变量当前值
分析:
- foo 返回了一个数组, 数组内是4个闭包函数, 闭包函数依赖2个外部变量: x 和 val
- foo 返回 fs 的时候, 仅仅是返回了一个闭包的定义, struct 定义中包含有“外部变量” x 和 val,但是 struct 中的 x 和 val 只是引用,并没有绑定值
- 第一次执行
f()时, 寻找 x 和 val 的最新值并绑定到闭包, 也即10 和 3 - 所以输出的%d 是 13,13,13,13
Goroutine 的闭包:
没有自由变量,没有形成真正的闭包:
func show(v interface{}) {
fmt.Printf("foo4 val = %v\n", v)
}
func foo4() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go show(val)
}
}
foo4() // 打印 1,2,3,5 (不一定按顺序)go 后面的匿名函数内,使用了自由变量,形成了闭包,所以外部变量会在“运行时”绑定:
func foo5() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go func() {
fmt.Printf("foo5 val = %v\n", val)
}()
}
}
foo5() // 打印 5,5,5,5
解析:
go func() {... } ()的写法,虽然最后带(),但匿名函数并没有立刻执行,只是将它加入任务队列等待调度;- 匿名函数使用了外部变量,也即形成了闭包,Go 对闭包的实现是定义一个 struct,该 struct 的成员包括函数返回地址和引用的环境中的变量地址;
- 匿名函数被 Goroution scheduler 调度到,以闭包的方式执行
@ref:
- 闭包的实现 · 深入解析Go:https://tiancaiamao.gitbooks.io/go-internals/content/zh/03.6.html
- Golang:“闭包(closure)”到底包了什么? - 知乎:https://zhuanlan.zhihu.com/p/92634505
控制语句
if可以先赋值再判断
if x:=computerValue(); x>y {
}按次数循环
// 循环1
for x:=0; x<10; x++ {
fmt.Println(x)
}
// 一直循环
for {
}遍历map/slice, 使用关键字
range:index, elem : = range sliceork, v := range map// 循环遍历 map
for k,v := range map[string]int {"one":1, "two":2} {
fmt.Println("%s %d\n", k,v)
}
// 循环遍历 slice
for i,s := range []string {"one","two"} {
fmt.Println("%d %s\n", i,s)
}switch
switch x {
case 1:
// 隐式break, 匹配到一个即停止
default:
}
type
golang中type的用法:
- 定义新类型:
type newType oldType// C++中的typedef用法是typedef oldType newType… - 定义结构体:
type STypeName struct{} 类型别名:
type rune = int32
type byte = uint8
type FloatType float32
// 类型别名2:
type S = string
var str S = "hello world"
// 函数别名:
type F = func()
var foo F = func() {
}
struct
定义:
type YourFirstStruct struct {
member1 string
member2 string
// 每个成员没有分号
}创建实例:
s := YourFirstStruct {
member1: "member1",
member2: "member2",
}golang 只有值传递, struct 在函数内/外传递 or 直接
=赋值给另一 struct 变量, 都会有一次拷贝;s1 := YourFirstStruct {
member1: ""
member2: ""
}
s2 := s1 // 赋值导致一次拷贝
// 避免拷贝的做法:
ptr1 := &YourFirstStruct {
}
ptr2 := ptr1 // 指针传递因为函数传参是值传递,所以在函数内对 struct 类型的参数进行更改,所修改的只是副本,如果需要实现在函数内对 struct 的修改,应该使用
*T类型作为形参;
type T struct{
Value int
}
func main(){
myT := T{Value:666}
change(&myT)
println(myT.Value)
}
func change(t *T){
t.Value = 999
}
给Struct添加方法, 无需C++那样的头文件声明, 直接定义方法:
// s被叫做“接收器”,第一种是“指针接收器”
func (s *YourFirstStruct) foo(param int) (ret int) {
}
// “值接收器”
func (s YourFirstStruct) foo2(param int) (ret int) {
}比较 struct 的“指针接收器” & “值接收器”
- 如果 func 内改变结构体的内容,需要“指针接收器”;
- 从性能比较,“值接收器” 需要更多次拷贝;
- 如果使用“值接收器”,因为函数内使用的是拷贝,所以func线程安全
interface
interface是一种类型, 包括0个或多个方法
type I interface {
Get() int
Set(int)
}空interface:
interface{}没有方法的interface, 可以认为任何类型都实现了该interface,func foo(any interface{}) {
// foo可以接受任何类型的参数
}Golang里没有extends这样的关键字来表名 某struct 实现了 某Interface, 只是在 赋值, 入参, 返回值 时被动检查
array
数组在编译期即指定大小
// 数组在用var声明时即分配了空间并给初始值
var arr0 [4]string
// 声明, 同时赋值
arr1 := [3]string {"a", "b", "c"}
arr2 := [...]string {"a", "b", "c"}golang在创建字面量数组时, 会根据数组长度进行不同的处理
- 数组len<=4, 直接在栈上分配数组
- 数组len>4, 会在静态区分配数组(编译期), 并在运行时取出来
- 上述没有考虑逃逸
数组的类型是:
[N]ElemType, 长度也算类型的一部分, 例如[10]int和[3]int是不同的类型在 golang 中,数组也是值传递,所以:
- 对于大型数组,应该使用 数组指针 or slice 的方式传递参数,避免拷贝;
- 如果要在函数内,修改函数外声明的数组,需要使用数组指针作为参数;
slice
- slice: Golang 内置类型, 即”动态数组” // 区别:数组的长度固定,不可改变
比较 slice 和 array 的声明方式
s2 := []int{1,2,3}字面量声明方式创建 slice- 如果上面使用
[N]or[...],创建出来的就不是 slice 而是 array 了
// 数组: 声明即分配空间
var arr0 [4]string
// 切片: 声明时没有分配空间
var slice0 []string
slice0[0] = 1 // panic: runtime error: index out of range
// 创建切片1, 通过数组
s1 := arr0[0:1]
// 创建切片2, 创建时给初值
s2 := []int{1,2,3}
// 创建切片3, len=cap=0
s3 := make([]int, 0)切片的扩容: 向切片add元素, 如果 len 大于 cap, 将创建新数组, 大小为原切面cap的两倍, 然后所有元素复制到新数组中
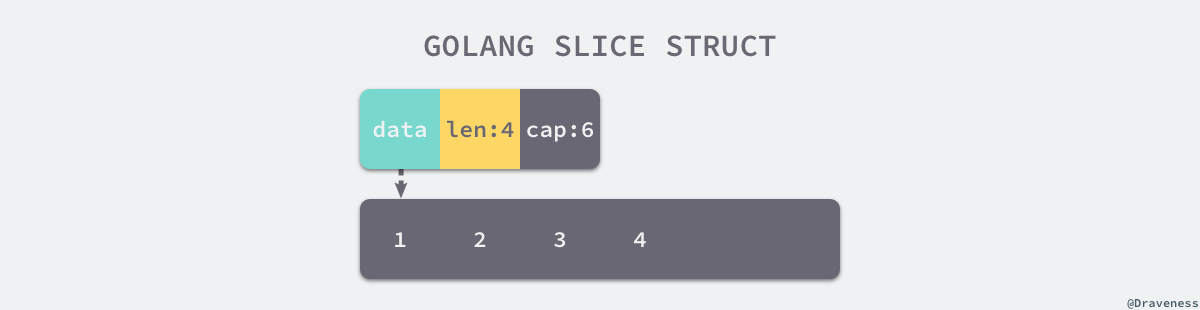
切片底层实现,由两部分组成: Header + 数组实际存储空间, 其中 Header 的结构表述如下
type SliceHeader struct {
array unsafe.Pointer // 指针, 指向连续的内存
len int
cap int
}
从数组创建切片:
slice := array[startIndex:endIndex], 切片将包含array[startIndex] ...array[endIdex-1], 这种方式创建的新数组, 只是新建了一个 slice 结构, data 指针指向的即是数组, 故修改 slice 的数据也会影响数组中的值:array := [5]int{1, 2, 3, 4, 5}
slice := array3[1:3] // 此时slice包括 [2,3], len=2, 但slice指向的数组是[2,3,4,5], 故cap=4
slice[0] = 7 // 对切片的修改也会影响数组, 但当切片发生一次扩容之后, 切片会指向一个新申请的数组空间复制切片:
slice3 := slice2[:]可以快速复制切片,但缺陷是slice3和slice2是同一个切片,无论改动哪个,另一个都会产生变化。内建函数copy可以用于复制 slice,并且两个 slice 各自使用独立的数组,见「内置函数」
➤ 比较数组和切片:
- 数组声明即分配空间, 且不可改变长度
- 切片声明不分配空间, 需要通过
make()orarr[start:end] - 切片的类型是
[]type, 数组的类型是[N]type
map
声明和初始化, 赋值, 访问:
// 声明
var mmap1 map[string]int
// 初始化
mmap1 = make(map[string]int)
// 赋值
mmap1["One"] = 1
// 访问
if v, exist := mmap1["One"]; exist {
delete(mmap1, "One")
}
// 声明+定义
mmap2 := map[string]string {"One":1, "Two":2}How to range map:
for k,v = range myMap {
fmt.Printf("%s %s", k, v)
}
chan
见第二部分
内置函数
@ref: https://pkg.go.dev/builtin#pkg-functions
len/cap
- len/cap: 返回数组, slice, map, string, chan ..的长度&容量
append/copy
- append: 切片拼接,原型:
func append(slice []Type, elems ...Type) []Type - copy:切片复制,原型:
func copy(dst, src []Type) int
print/println
- print:输出到 std err,原型:
func print(args ...Type) println:输出到 std err,arg 之间有空格,且有换行,原型:
func println(args ...Type)区分
fmt.Print(),输出到 standard output
make
func make(t Type, size ...IntegerType) Type |
- slice:
- make([]T)
- make([]T, len)
- make([]T, len, cap)
- map:
- make(map[K]V)
- make(map[K]V, cap)
- chan:
- make(chan T, cap)
new
- 原型:
func new(Type) *Type - 作用: 返回为指定类型分配的内存地址,分配的内存置零
example:
type YourStruct struct {
member1 int
}
// 创建struct方式1
p1 := new(YourStruct)
p1.member1 = 2
// 创建struct方式2
p2 := &YourStruct{ ... }Golang 中 new 和 var ,一个返回指针一个返回变量,二者的实现没有本质区别,都是要通过逃逸分析判断是在栈上/堆上分配变量(如果没有逃逸,new 创建的变量也可能在栈上创建)
make vs new
- new(T):
- 分配一块内存,内存置零,返回其指针(并未初始化)
- 根据new(T)的T创建内存,返回
*T类型,p := new(Type)等同于p := & Type{}
- make(T):
- 分配一块内存,并初始化,返回地址
- make只能用于初始化slice/map/chan
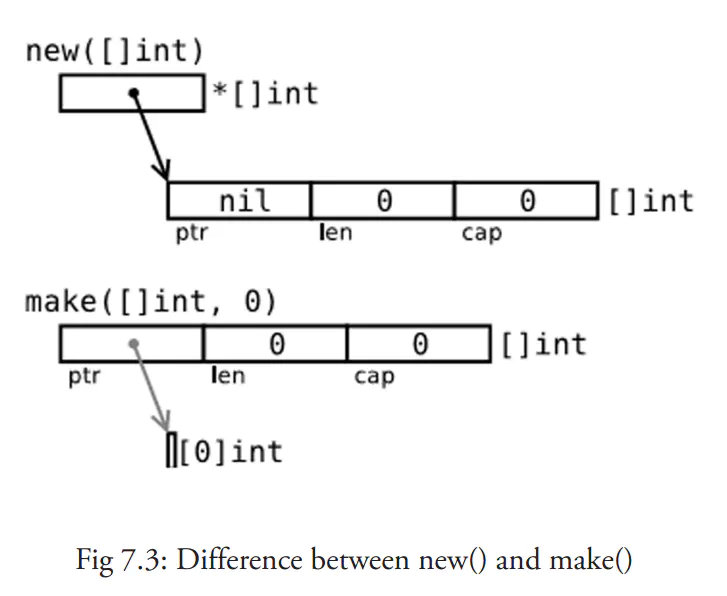
比较:
new([]int)只分配了一片内存(指向[]int类型,也就是 slice 的头)但是这块内存的 ptr 并未初始化;make([]int)为 slice 的 prt 做了初始化;
@ref:
delete
- delete: 用于删除 map 里的 key, 原型:
func delete(m map[Type]Type1, key Type)
close
- 关闭 chan,原型
func close(c chan<- Type)
close() 只能由 sender 调用,不可以由 receiver 调用,一旦对 chan 使用了 close,在接收完最后一个值后,该 chan 将被关闭,任何从该 chan 的 receive 都会返回 success 而不会阻塞;
panic & recovery
panic: panic 会停止当前 Goroutine 的正常执行,相当于其他编程语言的抛异常
- 原型:
func panic(v any) - 行为:
- 当函数 F 调用了 panic,F 的执行会被停止,在 F 中 panic 前面定义的 defer 操作都会被执行,然后 F 函数返回给调用者 G。
- 对于 G,调用 F 的行为类似于调用 panic,G 将调用 defer 函数,并返回给上一层调用者,直到程序非零值退出(除非调用了recover)
recovery:让程序从 panic 中恢复,阻止 panic 继续向上层调用者传播。返回类型是 any,返回的值是传入 panic(v) 的参数,recovery 必须在 defer 块中调用
- 原型:
func recover() any
➤ panic & recovery 使用示例:
func main() { |
@ref: https://pkg.go.dev/builtin#panic
➤ defer 关键字 → [[#defer]]
error
error是一个Interface:type error interface {
// 接口只有一个函数,返回字符串
Error() string
}使用
errors创建一个错误:err := errors.New("Error occured!"), 返回的是一个type errorString struct类型的错误- 定义自己的 error 类型: 定义错误的 Struct 类型, 然后实现
Error() string方法即可
defer
- 函数内定义的 defer 后的表达式,在函数退出前执行;
- 一个 func 可以有多个 defer 语句, defer 语句被压入栈中,所以函数退出时执行顺序与 defer 定义顺序相反;
- 如果 defer 之后是一个带参函数,例如
defer f(i),运行至 defer 时会立刻保存 i 的值(类似于一次值拷贝); - 如果 defer 之后形成了闭包(匿名函数内使用了外部变量),那么对外部变量的处理与闭包类似,在闭包实际运行时读取外部变量的最新值
func DeferEtudes3() { |
@ref::
➤ defer 的实现:
- 编译器将 defer 关键字转换为调用
runtime.deferproc()函数,这个函数接收了参数的大小和闭包所在的地址两个参数。 - 在
runtime.deferproc()中,创建一个runtime._defer结构体,并为它的成员赋值:函数指针fn、程序计数器pc和栈指针sp,并将相关的参数拷贝到相邻的内存空间中,并将结构体加入_defer链表的开头; - 在调用 defer 的函数末尾,插入
runtime.deferreturn()函数的调用,该函数会从 Goroutine 的_defer链表中取出最前面的runtime._defer结构体 … - 以上 @ref: 理解 Go 语言 defer 关键字的原理 | Go 语言设计与实现
序列化
- 小写开头的成员默认不被序列化
- struct tag:
json:"var_name"指定序列化后的变量名 - struct tag:
json:"var_name,omitempty"如果成员值为”zero-value”, 序列化将不包括此字段 struct tag:
json:"-"序列化时跳过此字段type YourFirstStruct struct {
Mem1 string `json:"variable1"`
Mem2 string `json:"variable2,omitempty"`
Mem3 string `json:"-"`
// 每个成员没有分号
}Type(struct/map 等) → byte[]
slice_of_byte, err := json.Marshal(obj)
byte[] → Type
obj := interface{}
json_str := `{"Name":"X", "Age": 101}`
err := json.Unmarshal([]byte(json_str), &obj)
时间 API
- 获取 int64时间戳:
var timestampSec int32 = time.Now().Unix()
单元测试
https://geektutu.com/post/quick-go-test.html
命令行 & 环境
Usage: |
➤ 常用:
- 获取包并安装:
go get golang.org/x/tools/gopls@latest(源码默认下载到 $GOPATH/src) - 开启 Go module:
go env -w GO111MODULE=on,从 v1.13 版本开始这个选项默认开启
Go 1.11 引入了 Go Modules,不再使用 GOPATH 存储每个依赖包的 git checkout,而是通过项目目录下的 go.mod 记录依赖包
➤ Golang 的环境变量可以使用 go env 查看:
$GOROOT表示 Go SDK 的安装位置,它的值一般都是 $HOME/go$GOPATH表示工作空间的路径,用来保存 Go 项目代码和第三方依赖包$GOARCH表示目标机器的处理器架构,它的值可以是 386、amd64 或 arm。$GOOS表示目标机器的操作系统,它的值可以是 darwin、freebsd、linux 或 windows。$GOARM专门针对基于 arm 架构的处理器,它的值可以是 5~7,默认为 6。
- GOARM=5: 使用软件浮点(software floating point);当 CPU 没有 VFP 协同处理器时
- GOARM=6: 仅使用 VFPv1; 使用交叉编译时的默认使用此选项,通常在 ARM11 或更高版本的内核中使用(也支持 VFPv2 或更高版本)
- GOARM=7: 使用 VFPv3;通常在 Cortex-A 内核中使用